GRAB-Net: Graph-Based Boundary-Aware Network for Medical Point Cloud Segmentation
Authors: Yifan Liu, Wuyang Li, Jie Liu, Hui Chen, and Yixuan Yuan, Member, IEEE
Keywords: Point cloud segmentation, graph-based framework, boundary-aware segmentation.

Abstract
点云分割在许多医学应用中都是基础性的,例如动脉瘤夹闭和矫正手术规划。最近的方法主要集中在设计强大的局部特征提取器,但普遍忽视了物体边界周围的分割,这对临床实践极为有害,并降低了整体分割性能。为了解决这个问题,提出了一种基于图的边界感知网络(GRAB-Net),包括三个范式:基于图的边界感知模块(GBM)、外部边界上下文分配模块(OCM)和内部边界特征校正模块(IFM),用于医学点云分割。为了提高边界周围的分割性能,GBM被设计用于检测边界,并在图域中交换语义和边界特征之间的补充信息,其中语义-边界相关性在全局建模,并通过图推理交换信息线索。此外,为了减少降低边界外分割性能的上下文混淆,提出了OCM来构建上下文图,在这里,不同类别的点被赋予不同的上下文,由几何标志引导。另外,提出了IFM来以对比方式区分边界内部模糊的特征,其中提出了边界感知对比策略来促进判别式表示学习。在两个公开数据集IntrA和3DTeethSeg上进行了大量实验,证明了方法对于现有技术的优越性。
点云分割是医学应用领域的一种基础技术。例如,对3D扫描的牙科模型进行分割,有助于牙医模拟牙齿拔除、删除和重排,从而更好地预测治疗效果。另一个例子是对3D血管表面进行颅内分割,为动脉瘤夹闭手术过程提供有益的边界线索。在临床实践中,一种可行的方式是手动对物体进行分割,但这种方式费时费力,且容易出现观察者之间的差异。因此,迫切需要准确可靠的自动点云分割方法来获得定量评估。
近年来,提出了许多点云分割方法,可以根据设计理念分为三类。提取器方法详尽设计了各种局部特征提取器来提取信息丰富的表示。语义增强方法则尝试引入额外信息来增强原始语义特征。尽管取得了一些性能提升,但它们在物体边界附近的表现难以令人满意,这对于临床实践是有害的,因为许多操作(如动脉瘤夹闭和牙齿拔除)都是沿着边界线进行的。为解决这一问题,提出了边界感知方法,采用边界感知和边界感知对比策略。前一种策略通常是使用额外的分支预测边界掩码,并将其并入语义特征中;而后一种策略()则旨在以对比的方式区分边界附近模糊的特征。
尽管在边界区域取得了一些改进,但现有边界感知框架仍然存在两个挑战。首先,当前方法直接组合语义和边界特征,并通过局部特征提取对它们的关系进行建模,这忽视了全局语义和形状线索,导致对分割任务的约束不足。更具体地说,语义和形状线索隐藏在各自的特征中,我们希望网络能够全局感知这两种信息,即整个语义分布和完整的边界形状,从而为网络生成适当的分割特征提供足够的约束。然而,由于特征提取过程引入的局部性,现有工作只能感知部分隐藏信息。另外,当前方法采用的直接组合两种特征的做法相当粗糙,这增加了网络捕捉它们相互关联的难度。为解决这些限制,我们使用图技术全局细致地对语义-边界相关性进行建模。在图域中,对偶对应关系可以由动态构造的图连接来表示,从而捕捉全局范围依赖关系。在此基础上,执行图卷积以自适应交换所需信息,为生成具有更精细细节的特征提供充分约束。

第二个挑战在于特征提取过程中边界区域存在的上下文混淆问题,进一步导致了模糊的表示,即特征模糊性问题。例如,如图1所示,点A和B在坐标空间中很接近,因此它们的上下文(即特征提取的参与者)具有高度相似性。这种上下文混淆会导致网络产生相似的特征,进而做出相同的类别预测,而这两个点实际上应该属于不同的类别。为解决这一问题,对于预测边界之外的特征,我们致力于为不同类别的点分配不相似的上下文。考虑到边界是不同类别的自然几何分界线,我们可以将上下文重新表示为图连接,并切断穿过预测边界的连接,这样可以确保预测边界之外的点只与同一侧(即同一类别)的点相连,从而区分不同类别的上下文。
Methodology
本文提出了一种用于医学点云分割的GRAB-Net方法,包含三个关键组件:基于图的边界感知模块(GBM)、外边界上下文分配模块(OCM)和内边界特征矫正模块(IFM)。整体框架如图2所示。给定输入点云 $I \in \mathbb{R}^{N \times C}$,其中包含坐标 $P \in \mathbb{R}^{N \times 3}$ 和其他属性如法向量,$N$为点数,$C$为特征维度。首先利用共享编码器的双分支骨干网络提取语义特征$X_s \in \mathbb{R}^{N \times D}$和边界特征$X_b \in \mathbb{R}^{N \times D}$,其中$D$为特征维度。

图 2. 所提出框架的图示,由 (a) 基于图的边界感知模块 (GBM)、(b) 外边界上下文分配模块 (OCM) 和 (c) 内边界特征校正模块组成 (IFM)。 输入点云被输入双分支网络以分别提取语义特征和边界特征。 GBM 模型以及通过对偶图推理 (DGR) 点和边界特征之间的相互交换相关性。 最后,IFM以对比的方式进一步减少了边界内的特征模糊性。
GBM模块将点级特征$X_s$和$X_b$投影到语义节点$V_s$和边界节点$V_b$,在图域中全局建模$V_s$和$V_b$之间的关系并交换对偶信息,得到更新后的图节点$\hat{V}_s$和$\hat{V}_b$,进一步重投影为点级特征$\hat{X}_s$和$\hat{X}_b$。具体包括以下步骤:
-
相干节点投影:将骨干网络提取的点级特征$X_s, X_b \in \mathbb{R}^{N \times D}$投影到更紧凑的特征$V_s, V_b \in \mathbb{R}^{M \times D} (M<N)$,分别作为语义和边界图节点。
从原始点云$P \in \mathbb{R}^{N \times 3}$中均匀采样得到$M$个点的子集$P_{sub} \in \mathbb{R}^{M \times 3}$(图3中红色点)。对每个采样点$P^{sub}_i$,在$P$中搜索$k_1$个最近邻(包括$P^{sub}_i$)构成邻域$\mathcal{N}(P^{sub}_i)$。最后以排列不变方式聚合这些邻域点的特征:
$V_i = \gamma(\text{MAX}(h(X_{P_j}))), P_j \in \mathcal{N}_{k_1}(P^{sub}_i) \tag{1}$
其中$X_{P_j} \in X$为点$P_j$对应的特征,$\gamma, h$为多层感知机(MLP),$\text{MAX}$在点维度进行,$V_i \in \mathbb{R}^D$为采样点$P^{sub}_i$聚合后的图节点。聚合每个采样点$P^{sub}_i$的邻域语义和边界特征$X_s$和$X_b$,可以分别得到语义和边界图节点$V_s$和$V_b$。
-
对偶图推理(DGR):给定投影的语义节点$V_s$和边界节点$V_b$,可构建对偶图$\mathcal{G}_d = (\mathcal{V},\mathcal{A})$来促进信息交换。

图 3. 相干节点投影过程的图示。
B. 外边界上下文赋值模块(OCM)
该模块旨在解决特征提取过程中边界附近的上下文混淆问题,这可能会降低医学点云分割在边界周围的性能。提出的OCM通过利用图技术为边界附近的每个点赋予上下文。
1) 上下文图构建:
- 将每个点视为图节点,其上下文由与其他节点的图连接表示。
- 构建上下文图$G_c = (V_c, E_c)$,其中$V_c = \mathbf{X}_s$(待细化的语义特征),而$E_c \in \{0, 1\}^{|V_c| \times |V_c|}$是描述节点连接的邻接矩阵。
- 通过切断预测边界点$B$之间的连接(从边界logits $\mathbf{Y}_{bb}$获得)来分离不同类别点的上下文。
- 将$B$中的点视为内边界点$P_{in}$,其余点视为外边界点$P_{out}$。
- 第$i$个和第$j$个点之间的连接$E_{c_{i,j}}$定义为:
$$
E_{c_{i,j}} = \begin{cases}
1, & (\text{若 } P_j \in \mathcal{N}_{k_2}(P_i)) \land (d(P_i, P_j) < \min\limits_{P_k \in P_{in}} d(P_i, P_k)), \\
0, & \text{否则},
\end{cases}
$$
其中$\land$是逻辑与运算符。这确保跨越边界的连接被禁止,而外边界点$P_{out}$上的上下文混淆点被赋予适当的上下文。
2) 上下文图推理:
- 利用构建的上下文图$G_c$,执行图推理以产生具有清晰上下文的特征。
- 对邻接矩阵$E_c$进行自环和度数归一化,得到$\mathbf{A} = \mathbf{D}^{-\frac{1}{2}}(\mathbf{E}_c + \mathbf{I})\mathbf{D}^{-\frac{1}{2}}$,其中$\mathbf{I}$是单位矩阵,而$\mathbf{D}_{i,i} = \sum_j \mathbf{E}_{i,j}$, $\mathbf{D}_{i,j \neq i} = 0$。
- 基于归一化邻接矩阵$\mathbf{A}$执行图推理:
$$
\tilde{\mathbf{X}}_s = \text{ReLU}(\mathbf{A}\mathbf{V}_c\mathbf{W}),
$$
其中$\mathbf{W} \in \mathbb{R}^{D \times D}$是可训练参数,$\tilde{\mathbf{X}}_s$是推理后的语义特征。
- 将清晰的特征$\tilde{\mathbf{X}}_s$传递到MLP层,得到的logits $\mathbf{Y}_{es}$由交叉熵损失$\mathcal{L}_c = -\frac{1}{N}\sum_{i=1}^N \mathcal{CE}(\mathbf{Y}_{es_i}, \mathbf{Y}_{sgt_i})$监督,其中$\mathbf{Y}_{sgt_i}$是第$i$个
点的类别标注。
总之,OCM采用了一种新颖的上下文图构建策略,根据预测的边界为不同类别的点赋予不同的上下文。然后执行图推理以产生更少模糊的表示。

图 4. 上下文图构造和推理的图示。
C. 内边界特征校正模块(IFM)
OCM可以解决外边界点的上下文混淆问题,但由于缺乏几何标志,内边界点的特征仍然存在模糊,导致分割预测不准确。为了解决这一瓶颈,我们设计了IFM,通过精心设计的样本内对比和样本间边界感知对比来区分内边界处的混淆特征。
1) 样本内边界感知对比:
- 对于样本内对比,我们的目标是使内边界点处的类别特定嵌入与同类别的外边界点嵌入相似,但与不同类别的嵌入不同。
- 这样可以有效减少特征模糊,因为混淆的特征被优化朝着特征空间中正确的方向。
- 首先将特征通过两个后续的MLP层投影到特征嵌入E,并在嵌入空间中进行对比,遵循[34]。
- 对于属于内边界点的类别特定的锚嵌入Ei∈{Eu|Pu∈Pin},将属于k3最近非边界邻居且同类别的嵌入E+i={Eu|Ygtu=Ygti,Pu∈NPoutk3(Pi)}视为正嵌入,将属于k3最近非边界邻居但不同类别的嵌入E-i={Eu|Ygtu≠Ygti,Pu∈NPoutk3(Pi)}视为负嵌入。
- 选择k3最近邻居而不是所有非边界点的原因是,这些几何相邻的嵌入是困难样本,而困难的正/负样本已被证明比容易样本更有利于对比学习[34]。
- 为了约束锚嵌入与正/负嵌入的相似性,样本内边界感知对比损失Lintra定义为:
$$
L_{intra} = -\frac{1}{|B|}\sum_{E_i}\frac{1}{|K_i^+|}\sum_{E_j\in K_i^+}\log\frac{h_\theta(E_i, E_j)}{\sum_{E_k\in K_i^-}h_\theta(E_i, E_k)},
$$
其中$h_\theta(\cdot)$是相似度函数,我们采用指数余弦相似度:$h_\theta(p, q) = \exp(\frac{p\cdot q}{|p||q|}\cdot\frac{1}{\tau})$,其中$\tau$是温度因子。通过优化这个损失,模型可以区分内边界处的模糊特征。
2) 样本间边界感知对比:
- 最新研究表明,大量有效负样本对对比表示学习至关重要。而在样本内对比中,有效负嵌入的数量受当前点云样本大小的限制。
- 因此,我们提出样本间边界感知对比,以纳入其他样本的嵌入。
- 为此,我们在训练过程中维护一个外部记忆库M∈RL×C×D,其中L是训练样本长
度,C是类别数,D是特征维度。
- 在训练过程中,我们首先预热网络T个epoch以生成合理的嵌入,然后初始化记忆库MT。考虑到保存所有点级嵌入需要过多内存,我们只保存每个类别的平均嵌入(中值嵌入也是一种可行的健壮替代方案)。
- 然后在epoch t=T+1,...,对于每个样本,我们可以类似于等式8计算样本间对比损失Linter,但不同的是,用记忆库Mt-1中保存的嵌入替换正/负嵌入:E+i={Eu|Ygtu=Ygti,Eu∈Mt-1}, E-i={Eu|Ygtu≠Ygti,Eu∈Mt-1}。
- 计算Linter后,以动量方式更新记忆库:
$$
M_i^{t,c} = \alpha M_i^{t-1,c} + (1-\alpha)E_i^c
$$
其中$\alpha$是前一个和当前嵌入的平衡权重,而$E_i^c$是第i个训练样本中类别c的平均嵌入。这样,记忆库可以更新以保留适当的候选嵌入,与锚嵌入进行有效对比,促使混淆的锚特征朝着特征空间中正确的方向优化。
D. 优化
在训练过程中,我们联合优化GBM、OCM和IFM中的损失。首先在GBM中,语义的交叉熵损失Ls和边界的交叉熵损失Lb用于指导网络生成适当的表示。然后在OCM中,交叉熵损失Lc用于监督外边界预测特征的细化。最后,在IFM中,提出样本内损失Lintra和样本间损失Linter来区分内边界预测的模糊特征。
总之,所提GRAB-Net的总体目标函数为:
$$
L_{overall} = \lambda_1(L_s + L_b) + \lambda_2L_c + \lambda_3(L_{intra} + L_{inter})
$$
其中$\lambda_1$、$\lambda_2$和$\lambda_3$是平衡每一项贡献的权重因子。


图5 颅内分割结果的几个典型例子。 每行代表 (a) PointNet++ [8]、(b) PointConv [11]、(c) PCT [16]、(d) PAConv [17] (e) PointTransformer [18]、(f) CBL [ 25],(g)Ours,(h)Ground Truth。 请注意,右下角的标量代表 B-IoU 量,用于衡量边界区域周围的分割性能。


图6.牙齿分割结果的两个典型示例。 每行代表 (a) PCT [16]、(b) PAConv [17]、(c) PointTransformer [18]、(d) CBL [25]、(e) Ours 和 (f) ground Truth 的结果。



1. 消融实验:
- 单独添加GBM、OCM和IFM模块都能提高基线的性能,表明全局建模语义-边界关联、纠正混淆的上下文以及区分模糊特征的优势。
- 结合任意两个或所有三个模块的性能优于单独使用一个模块,证实了它们的兼容性。
2. GBM中的投影节点数量:
- 节点数过少(如32)会因投影过程中的信息损失而导致性能不佳。
- 节点数增多会提高性能,但过多(如超过128)会饱和并下降。
- 64个节点在信息保留和澄清之间达到最佳平衡。
3. OCM中的图推理层数:
- 2层性能最佳。1层不足以传播信息,而3层以上可能过拟合。
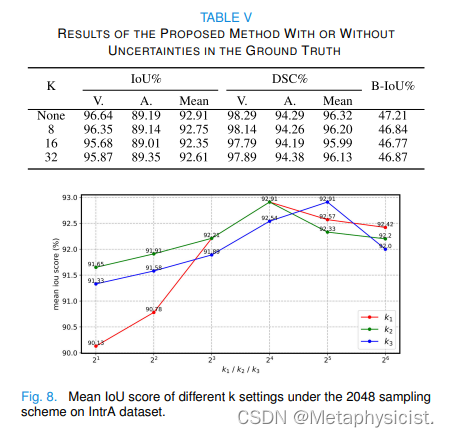
4. 最近邻居数k1, k2, k3:
- 这些影响一致性节点投影、上下文图构建和边界感知对比。
- 分析表明性能对k值的选择很敏感。
5. 标签不确定性的影响:
- 在损失函数中考虑标签不确定性可提高分割性能。
6. 在IntrA和3DTeethSeg数据集上的结果:
- 所提出的方法在两个数据集上都优于现有的三维分割方法,尤其在边界区域。
- 定性结果直观地展示了该方法在各种形状的血管瘤和牙齿分割中的优越性。
Reference
[1] Liu, Y., Li, W., Liu, J., Chen, H., & Yuan, Y. (2023). GRAB-Net: Graph-based boundary-aware network for medical point cloud segmentation. IEEE Transactions on Medical Imaging.









