def get_rotate_theta(from_landmarks, to_landmarks):
from_left_eye = from_landmarks[36]
from_right_eye = from_landmarks[45]
to_left_eye = to_landmarks[36]
to_right_eye = to_landmarks[45]
from_angle = math.atan2(from_right_eye[1] - from_left_eye[1], from_right_eye[0] - from_left_eye[0])
to_angle = math.atan2(to_right_eye[1] - to_left_eye[1], to_right_eye[0] - to_left_eye[0])
from_theta = -from_angle * (180 / math.pi)
to_theta = -to_angle * (180 / math.pi)
return to_theta - from_theta
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
to_video函数主要是用来创建一个视频生成器的。get_equation函数是用来生成一个根据时间变化的方程,主要用到了一次方程和二次方程。get_rotate_theta这个函数是通过计算左右眼的夹角来估计人脸倾斜角度差值,下标的值可以参考第一张图片。
最后我们就要进入主函数的实现了,主要思路是遍历所有图片,每个迭代拿出当前图和下一张图,然后识别出两张人脸中的关键点,通过这些关键点我们可以计算出两张图在某一时刻需要的旋转角度、旋转中心、缩放比例、位移像素数等关键参数。最终我们再次迭代frames_per_transformer次通过对两张图片分别做旋转、平移变换来达到效果。
def compose_img(name, frames_per_transformer, wait_frames, *imgs):
video_writer = to_video(“{}.avi”.format(name), imgs[0].shape[1], imgs[0].shape[0])
img_count = len(imgs)
for idx in range(img_count - 1):
from_img = imgs[idx]
to_img = imgs[idx + 1]
from_width = from_img.shape[1]
from_height = from_img.shape[0]
to_width = to_img.shape[1]
to_height = to_img.shape[0]
from_face_region, from_landmarks = face_detector(from_img)
to_face_region, to_landmarks = face_detector(to_img)
第一张图最终的旋转角度
from_theta = get_rotate_theta(from_landmarks, to_landmarks)
第二张图初始的旋转角度
to_theta = get_rotate_theta(to_landmarks, from_landmarks)
两张图的旋转中心
from_rotate_center = (from_face_region.left() + (from_face_region.right() - from_face_region.left()) / 2, from_face_region.top() + (from_face_region.bottom() - from_face_region.top()) / 2)
to_rotate_center = (to_face_region.left() + (to_face_region.right() - to_face_region.left()) / 2, to_face_region.top() + (to_face_region.bottom() - to_face_region.top())/2)
from_face_area = from_face_region.area()
to_face_area = to_face_region.area()
第一张图的最终缩放因子
to_scaled = from_face_area / to_face_area
第二张图的初始缩放因子
from_scaled = to_face_area / from_face_area
平移多少的基准
to_translation_base = to_rotate_center
from_translation_base = from_rotate_center
equation_pow = 1 if idx % 2 == 0 else 2
建立变换角度的方程
to_theta_f = get_equation(0, to_theta, frames_per_transformer - 1, 0, equation_pow)
from_theta_f = get_equation(0, 0, frames_per_transformer - 1, from_theta, equation_pow)
建立缩放系数的角度
to_scaled_f = get_equation(0, to_scaled, frames_per_transformer - 1, 1, equation_pow)
from_scaled_f = get_equation(0, 1, frames_per_transformer - 1, from_scaled, equation_pow)
for i in range(frames_per_transformer):
当前时间点的旋转角度
cur_to_theta = to_theta_f(i)
cur_from_theta = from_theta_f(i)
当前时间点的缩放因子
cur_to_scaled = to_scaled_f(i)
cur_from_scaled = from_scaled_f(i)
生成第二张图片变换矩阵
to_rotate_M = cv2.getRotationMatrix2D(to_rotate_center, cur_to_theta, cur_to_scaled)
对第二张图片执行仿射变换
to_dst = cv2.warpAffine(to_img, to_rotate_M, (to_width, to_height), borderMode=cv2.BORDER_REPLICATE)
生成第一张图片的变换矩阵
from_rotate_M = cv2.getRotationMatrix2D(from_rotate_center, cur_from_theta, cur_from_scaled)
对第一张图片执行仿射变换
from_dst = cv2.warpAffine(from_img, from_rotate_M, (from_width, from_height), borderMode=cv2.BORDER_REPLICATE)
重新计算变换后的平移基准
to_left_rotated = to_rotate_M[0][0] * to_translation_base[0] + to_rotate_M[0][1] * to_translation_base[1] + to_rotate_M[0][2]
to_top_rotated = to_rotate_M[1][0] * to_translation_base[0] + to_rotate_M[1][1] * to_translation_base[1] + to_rotate_M[1][2]
from_left_rotated = from_rotate_M[0][0] * from_translation_base[0] + from_rotate_M[0][1] * from_translation_base[1] + from_rotate_M[0][2]
from_top_rotated = from_rotate_M[1][0] * from_translation_base[0] + from_rotate_M[1][1] * from_translation_base[1] + from_rotate_M[1][2]
当前时间点的平移数
to_left_f = get_equation(0, from_left_rotated - to_left_rotated, frames_per_transformer - 1, 0, equation_pow)
to_top_f = get_equation(0, from_top_rotated - to_top_rotated, frames_per_transformer - 1, 0, equation_pow)
from_left_f = get_equation(0, 0, frames_per_transformer - 1, to_left_rotated - from_left_rotated, equation_pow)
from_top_f = get_equation(0, 0, frames_per_transformer - 1, to_top_rotated - from_top_rotated, equation_pow)
生成第二张图片平移的变换矩阵
to_translation_M = np.float32(
[
[1, 0, to_left_f(i)],
[0, 1, to_top_f(i)]
]
)
对第二张图片执行平移变换
to_dst = cv2.warpAffine(to_dst, to_translation_M, (to_width, to_height), borderMode=cv2.BORDER_REPLICATE)
生成第一张图片平移的变换矩阵
from_translation_M = np.float32(
[
[1, 0, from_left_f(i)],
[0, 1, from_top_f(i)]
]
)
对第一张图片执行平移变换
from_dst = cv2.warpAffine(from_dst, from_translation_M, (from_width, from_height), borderMode=cv2.BORDER_REPLICATE)
将两张图片合成到一张,并写入视频帧
new_img = cv2.addWeighted(from_dst, 1 - ((i + 1) / frames_per_transformer), to_dst, (i + 1) / frames_per_transformer, 0)
video_writer.write(new_img)
一个迭代完成,迭代n次写入第二张图片
for _ in range(wait_frames):
video_writer.write(to_img)
video_writer.release()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
以上就是利用仿射变换实现的代码。效果可以看下面的gif(忽略gif的颜色问题,视频正常!完整视频可以到http://www.iqiyi.com/w_19saz225ol.html查看)
通过观察效果和代码,我们来总结一下这个版本的不足之处:
两张人脸并未真正实现大小一致。
人脸对齐也做的不够好。
仅在2D空间做了变换,对于脸朝向的变换不敏感。
代码复杂。
仅利用了68个人脸关键点中的一小部分,并未充分利用人脸的特征。
以上几个问题其实就决定了仿射变换版本的使用局限性很大,跟抖音实现的效果差距很大。这也迫使我寻找另一种解决方案,结果就是透视变换版本,这个版本代码简单而且效果更接近抖音。
透视变换
仿射变换仅在二维空间做线性变换和平移,所以两条平行线变换后还是平行的,因而我们感受不到立体变换的效果。而透视变换则不同,它是在3D空间做变换,最后在映射到2D平面。以下是透视变换的数学原理。
⎡⎣x′y′z⎤⎦=⎡⎣a11a21a31a12a22a32a13a23a33⎤⎦∗⎡⎣xy1⎤⎦ \left[\begin{matrix}x’ \y’ \z\end{matrix} \right]=\left[\begin{matrix}a_{11} & a_{12} & a_{13} \a_{21} & a_{22} & a_{23} \a_{31} & a_{32} & a_{33}\end{matrix} \right]*\left[\begin{matrix}x \y \1\end{matrix} \right]
⎣
⎡
x
′
y
′
z
⎦
⎤
⎣
⎡
a
11
a
21
a
31
a
12
a
22
a
32
a
13
a
23
a
33
⎦
⎤
∗
⎣
⎡
x
y
1
⎦
⎤
从公式中可以看到变换后做了第3个维度z。展开为方程组形式:
⎧⎩⎨⎪⎪x′=a11∗x+a12∗y+a13y′=a21∗x+a22∗y+a23z=a31∗x+a32∗y+a33 \begin{cases}x’=a_{11}*x+a_{12}*y+a_{13} \y’=a_{21}*x+a_{22}*y+a_{23} \z=a_{31}*x+a_{32}*y+a_{33}\end{cases}
⎩
⎪
⎨
⎪
⎧
x
′
=a
11
∗x+a
12
∗y+a
13
y
′
=a
21
∗x+a
22
∗y+a
23
z=a
31
∗x+a
32
∗y+a
33
最后映射回2维空间:
⎧⎩⎨x′=x′z=a11∗x+a12∗y+a13a31∗x+a32∗y+a33y′=y′z=a21∗x+a22∗y+a23a31∗x+a32∗y+a33 \begin{cases}x’=\frac{x’}{z}=\frac{a_{11}*x+a_{12}*y+a_{13}}{a_{31}*x+a_{32}*y+a_{33}} \y’=\frac{y’}{z}=\frac{a_{21}*x+a_{22}*y+a_{23}}{a_{31}*x+a_{32}*y+a_{33}}\end{cases}
{
x
′
z
x
′
a
31
∗x+a
32
∗y+a
33
a
11
∗x+a
12
∗y+a
13
y
′
z
y
′
a
31
∗x+a
32
∗y+a
33
a
21
∗x+a
22
∗y+a
23
从公式中可以看到,假设将a33设为1,那么会有8个未知数,也就是我们至少需要4个点才能求得方程的接。在python中可以轻松的实现:
img = cv2.imread(“./1.jpg”)
src_pts = np.float32(
[
[
[0, 0],
[0, 626],
[500, 626],
[500, 0]
]
])
dst_pts = np.float32(
[
[100, 50],
[150, 200],
[500, 626],
[500, 0]
]
)
M = cv2.getPerspectiveTransform(src_pts, dst_pts)
dst = cv2.warpPerspective(img, M, (img.shape[0], img.shape[1]))
cv2.imshow(“”, dst)
cv2.waitKey()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
上面代码效果如下:
上面的代码是通过getPerspectiveTransform函数找到src的4个点和dst的4个点的变换矩阵,还有一个函数findHomography可以在一堆点中找到最佳的变换矩阵,很明显,第二个函数更符合这个需求的实现,可以直接将人脸识别后的关键点扔给这个函数,然后找到最佳变换矩阵。所以透视变换版本的代码如下:
def compose_img(name, frames_per_transformer, wait_frames, *imgs):
video_writer = to_video(“{}.avi”.format(name), imgs[0].shape[1], imgs[0].shape[0])
img_count = len(imgs)
for idx in range(img_count - 1):
from_img = imgs[idx]
to_img = imgs[idx + 1]
from_width = from_img.shape[1]
from_height = from_img.shape[0]
to_width = to_img.shape[1]
to_height = to_img.shape[0]
equation_pow = 1 if idx % 2 == 0 else 2
from_face_region, from_landmarks = face_detector(from_img)
to_face_region, to_landmarks = face_detector(to_img)
homography_equation = get_equation(0, from_landmarks, frames_per_transformer - 1, to_landmarks, equation_pow)
for i in range(frames_per_transformer):
from_H, _ = cv2.findHomography(from_landmarks, homography_equation(i))
to_H, _ = cv2.findHomography(to_landmarks, homography_equation(i))
from_dst = cv2.warpPerspective(from_img, from_H, (from_width, from_height), borderMode=cv2.BORDER_REPLICATE)
to_dst = cv2.warpPerspective(to_img, to_H, (to_width, to_height), borderMode=cv2.BORDER_REPLICATE)
new_img = cv2.addWeighted(from_dst, 1 - ((i + 1) / frames_per_transformer), to_dst, (i + 1) / frames_per_transformer, 0)
video_writer.write(new_img)
for _ in range(wait_frames):
video_writer.write(to_img)
video_writer.release()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则近万的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Android)

文末
初级工程师拿到需求会直接开始做,然后做着做着发现有问题了,要么技术实现不了,要么逻辑有问题。
而高级工程师拿到需求会考虑很多,技术的可行性?对现有业务有没有帮助?对现有技术架构的影响?扩展性如何?等等…之后才会再进行设计编码阶段。
而现在随着跨平台开发,混合式开发,前端开发之类的热门,Android开发者需要学习和掌握的技术也在不断的增加。
通过和一些行业里的朋友交流讨论,以及参考现在大厂面试的要求。我们花了差不多一个月时间整理出了这份Android高级工程师需要掌握的所有知识体系。你可以看下掌握了多少。
混合式开发,微信小程序。都是得学会并且熟练的
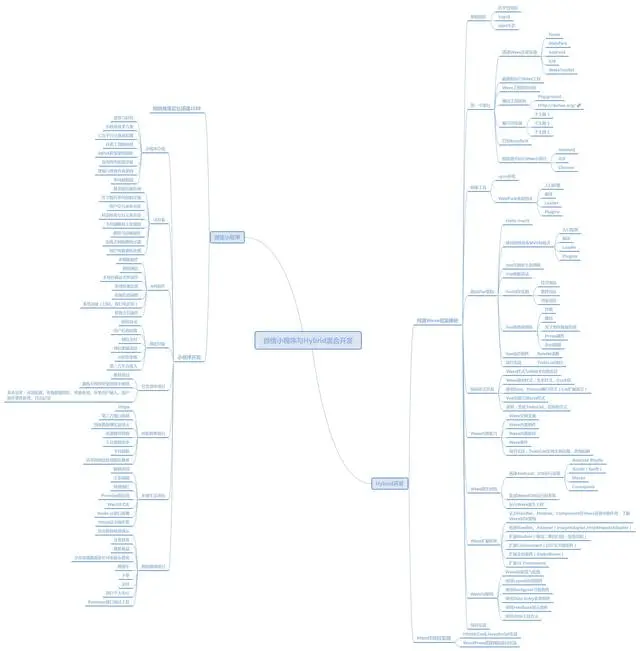
这些是Android相关技术的内核,还有Java进阶
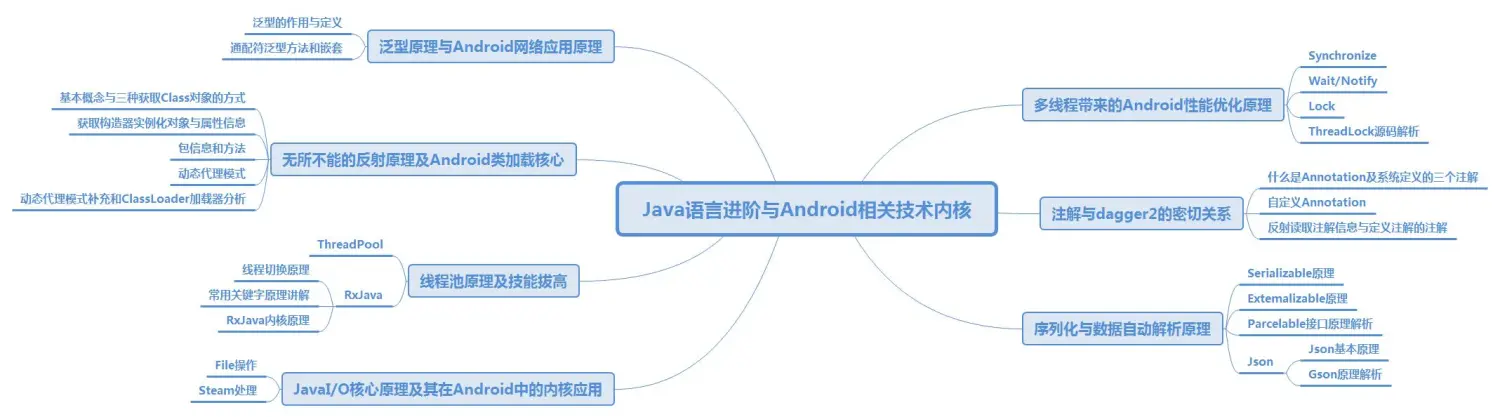
高级进阶必备的一些技术。像移动开发架构项目实战等
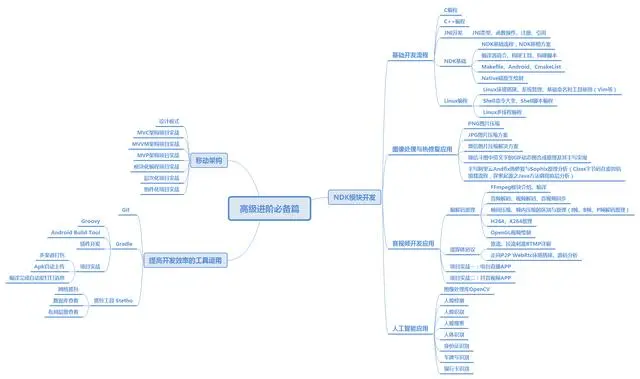
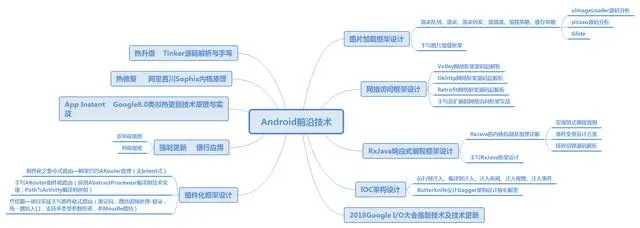
Android前沿技术;包括了组件化,热升级和热修复,以及各种架构跟框架的详细技术体系
以上即是我们整理的Android高级工程师需要掌握的技术体系了。可能很多朋友觉得很多技术自己都会了,只是一些新的技术不清楚而已。应该没什么太大的问题。
而这恰恰是问题所在!为什么别人高级工程师能年限突破30万,而你只有十几万呢?
就因为你只需补充你自己认为需要的,但并不知道企业需要的。这个就特别容易造成差距。因为你的技术体系并不系统,是零碎的,散乱的。那么你凭什么突破30万年薪呢?
我这些话比较直接,可能会戳到一些人的玻璃心,但是我知道肯定会对一些人起到点醒的效果的。而但凡只要有人因为我的这份高级系统大纲以及这些话找到了方向,并且付出行动去提升自我,为了成功变得更加努力。那么我做的这些就都有了意义。
喜欢的话请帮忙转发点赞一下能让更多有需要的人看到吧。谢谢!
《Android学习笔记总结+移动架构视频+大厂面试真题+项目实战源码》,点击传送门即可获取!
有Java进阶
[外链图片转存中…(img-Wg3AnaN8-1712380855379)]
高级进阶必备的一些技术。像移动开发架构项目实战等
[外链图片转存中…(img-x3QJV3d0-1712380855379)]
Android前沿技术;包括了组件化,热升级和热修复,以及各种架构跟框架的详细技术体系
[外链图片转存中…(img-z6RYxuxX-1712380855379)]
以上即是我们整理的Android高级工程师需要掌握的技术体系了。可能很多朋友觉得很多技术自己都会了,只是一些新的技术不清楚而已。应该没什么太大的问题。
而这恰恰是问题所在!为什么别人高级工程师能年限突破30万,而你只有十几万呢?
就因为你只需补充你自己认为需要的,但并不知道企业需要的。这个就特别容易造成差距。因为你的技术体系并不系统,是零碎的,散乱的。那么你凭什么突破30万年薪呢?
我这些话比较直接,可能会戳到一些人的玻璃心,但是我知道肯定会对一些人起到点醒的效果的。而但凡只要有人因为我的这份高级系统大纲以及这些话找到了方向,并且付出行动去提升自我,为了成功变得更加努力。那么我做的这些就都有了意义。









