本文目录:
一、爬虫的基本概念
1.为什么要学习爬虫
如今,人工智能,大数据离我们越来越近,很多公司在开展相关的业务,但是人工智能和大数据中有一个东西非常重要,那就是数据,但是数据从哪里来呢?
首先我们来看下面这个例子:
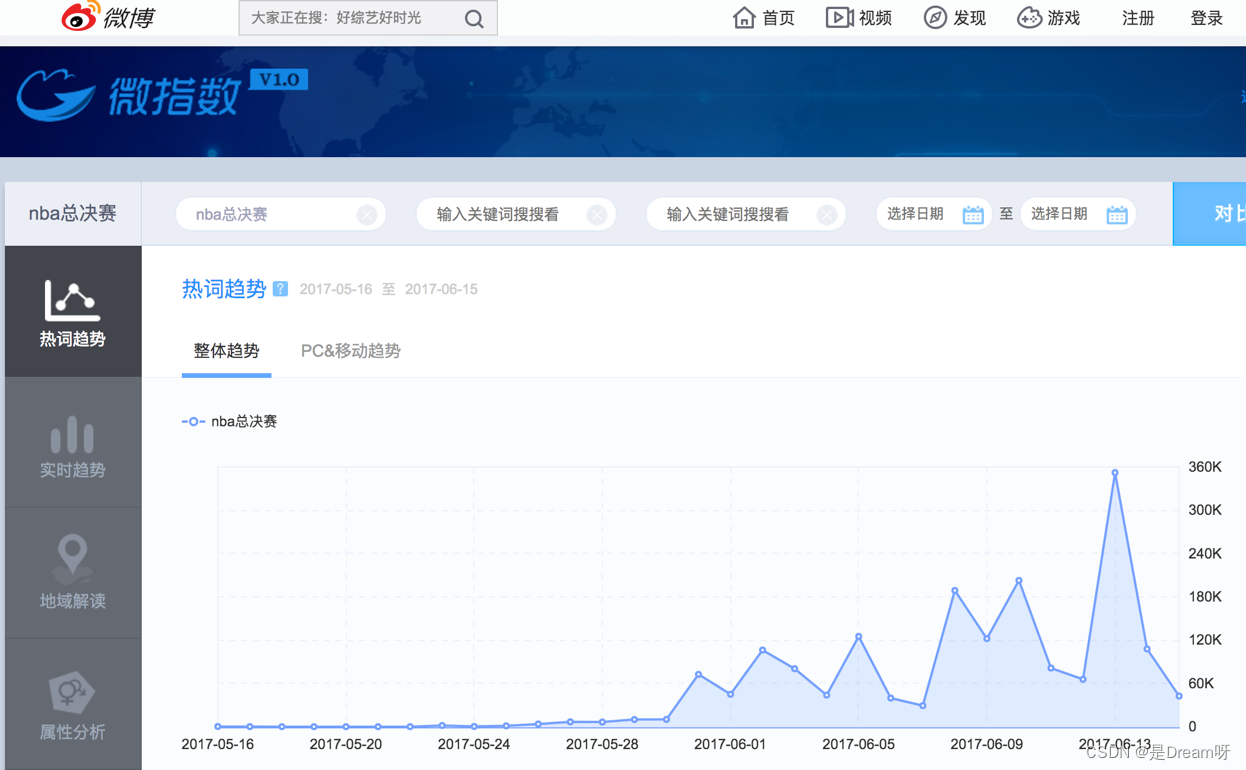
这是微博的微指数的一个截图,他把在微博上的用户的微博和评论中的关键词语做了提取,然后进行了统计,然后根据统计结果得出某个词语的流行趋势,之后进行了简单的展示
类似微指数的网站还有很多,比如百度指数,阿里指数,360指数等等,这些网站有非常大的用户量,他们能够获取自己用户的数据进行统计和分析
那么对于一些中小型的公司,没有如此大的用户量的时候,他们该怎么办呢?
1.1 数据的来源
- 去第三方的公司购买数据(比如企查查)
- 去免费的数据网站下载数据(比如国家统计局)
- 通过爬虫爬取数据
- 人工收集数据(比如问卷调查)
在上面的来源中:人工的方式费时费力,免费的数据网站上的数据质量不佳,很多第三方的数据公司他们的数据来源往往也是爬虫获取的,所以获取数据最有效的途径就是通过爬虫爬取
1.2 爬取到的数据用途

通过前面的列子,能够总结出,爬虫获取的数据的用途:
- 进行在网页或者是app上进行展示
- 进行数据分析或者是机器学习相关的项目
2.什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做
3. 爬虫的更多用途
-
12306抢票
-
网站上的投票
-
短信轰炸
二、爬虫的分类和爬虫的流程
- 了解 爬虫分类
- 记忆 爬虫流程
- 了解 robots协议
1.爬虫的分类
根据被爬网站的数量的不同,我们把爬虫分为:
-
通用爬虫 :通常指搜索引擎的爬虫(https://www.baidu.com)
-
聚焦爬虫 :针对特定网站的爬虫
2.爬虫的流程
爬虫的工作流程:

- 向起始url发送请求,并获取响应
- 对响应进行提取
- 如果提取url,则继续发送请求获取响应
- 如果提取数据,则将数据进行保存
3.robots协议
Robots协议:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是互联网中的一般约定
三、爬虫http和https

在发送请求,获取响应的过程中 就是发送http或https的请求,获取http或https的响应
1.http和https的概念
- HTTP
- 超文本传输协议
- 默认端口号:80
- HTTPS
- HTTP + SSL(安全套接字层),即带有安全套接字层的超本文传输协议
- 默认端口号:443
HTTPS比HTTP更安全,但是性能更低
2.浏览器发送HTTP请求的过,
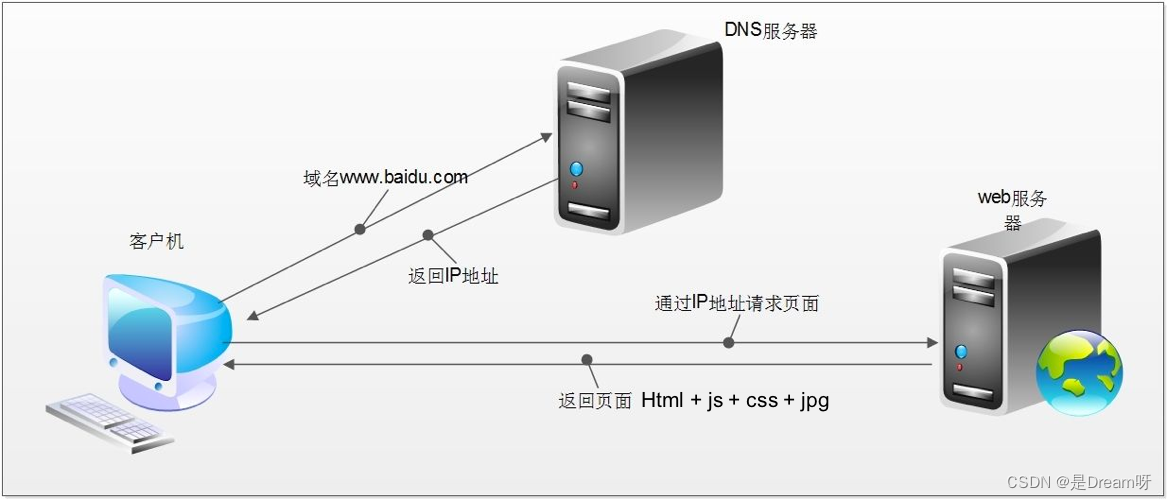
2.1 http请求的过程
-
浏览器先向地址栏中的url发起请求,并获取相应
-
在返回的响应内容(html)中,会带有css、js、图片等url地址,以及ajax代码,浏览器按照响应内容中的顺序依次发送其他的请求,并获取相应的响应
-
浏览器每获取一个响应就对展示出的结果进行添加(加载),js,css等内容会修改页面的内容,js也可以重新发送请求,获取响应
-
从获取第一个响应并在浏览器中展示,直到最终获取全部响应,并在展示的结果中添加内容或修改————这个过程叫做浏览器的渲染
2.2 注意:
但是在爬虫中,爬虫只会请求url地址,对应的拿到url地址对应的响应(该响应的内容可以是html,css,js,图片等)
浏览器渲染出来的页面和爬虫请求的页面很多时候并不一样
所以在爬虫中,需要以url地址对应的响应为准来进行数据的提取
3.HTTP请求的形式
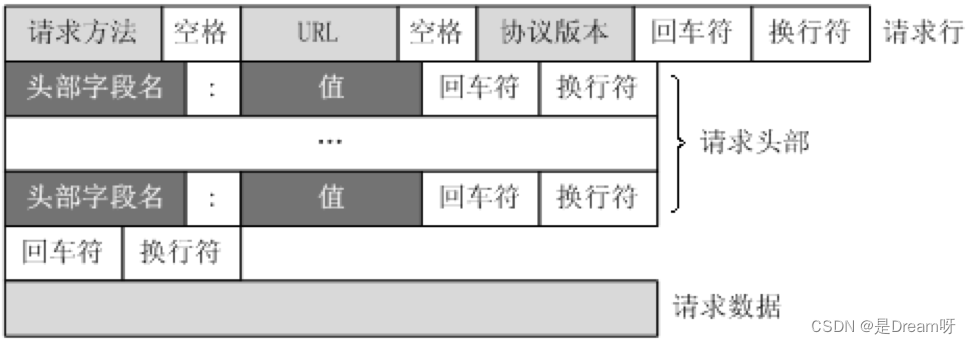
这个图大家见过很多次,那么在浏览器headers中,点击view source来具体观察其中的请求行,请求头部和请求数据是什么样子的
4.HTTP常见请求头
- Host (主机和端口号)
- Connection (链接类型)
- Upgrade-Insecure-Requests (升级为HTTPS请求)
- User-Agent (浏览器名称)
- Accept (传输文件类型)
- Referer (页面跳转处)
- Accept-Encoding(文件编解码格式)
- Cookie (Cookie)
- x-requested-with :XMLHttpRequest (表示该请求是Ajax异步请求)
5.响应状态码(status code)
常见的状态码:
- 200:成功
- 302:临时转移至新的url
- 307:临时转移至新的url
- 404:找不到该页面
- 500:服务器内部错误
- 503:服务不可用,一般是被反爬
记忆 http请求头的形式:
GET /item/503/1227315?fr=aladdin HTTP/1.1
Host: www.baidu.com
记忆 http响应头的形式 :
HTTP/1.1 200 OK
Connection: keep-alive
了解 http响应状态码
- 200:成功
- 302:临时转移至新的url
获取免费代理ip











