什么是etcd?
Kubernetes 为什么用 etcd ?
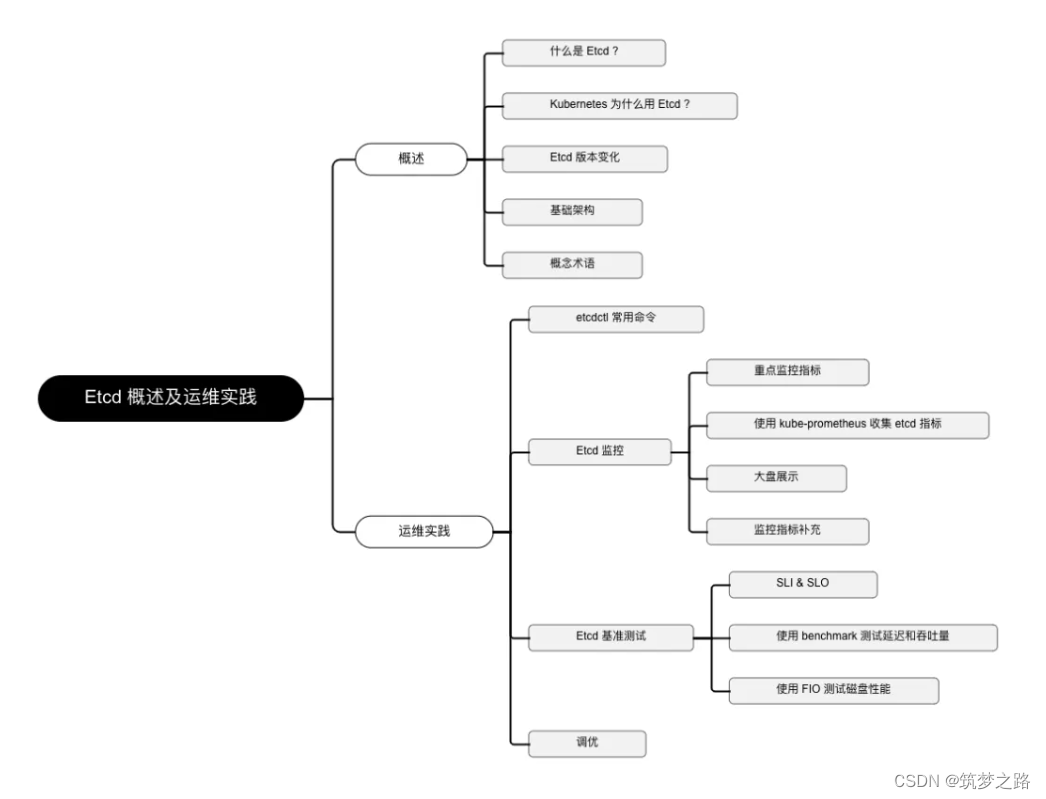
Etcd 版本变化
时间轴
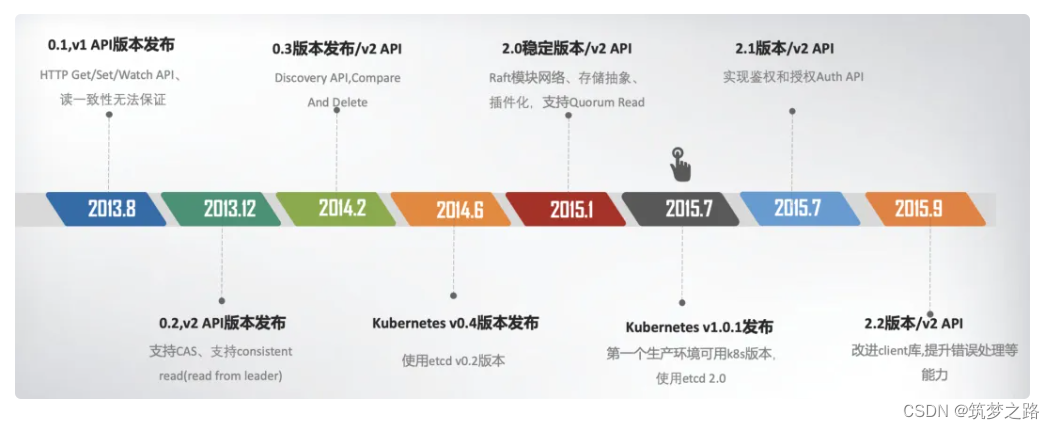 随着 Kubernetes 项目不断发展,v2 版本的瓶颈和缺陷逐渐暴露,遇到了若干性能和稳定性问题
随着 Kubernetes 项目不断发展,v2 版本的瓶颈和缺陷逐渐暴露,遇到了若干性能和稳定性问题
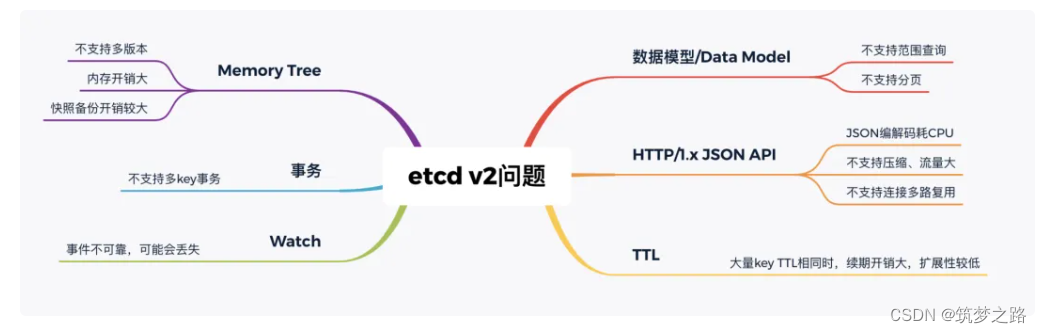
2016年6月,etcd 3.0 诞生,随后 Kubernetes 1.6 发布,默认启用 etcd v3,助力 Kubernetes 支撑5000节点集群规模

v3方案的发布,也标志着 etcd 进入了技术成熟期,成为云原生时代的首选元数据存储产品。
基础架构
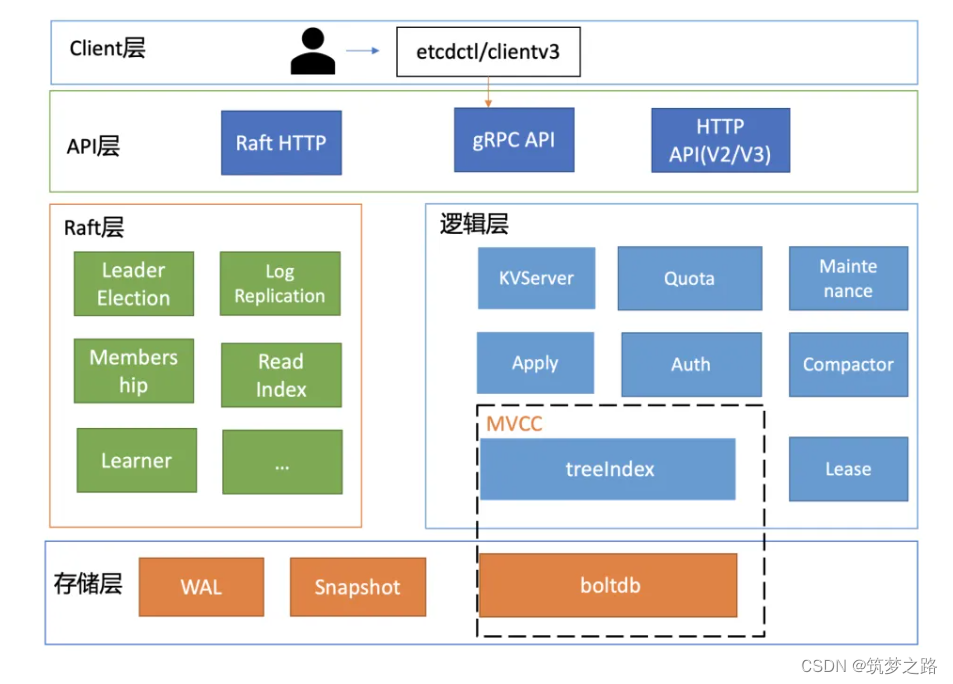 按照分层模型,etcd 可分为 Client 层、API 网络层、Raft 算法层、逻辑层和存储层。
按照分层模型,etcd 可分为 Client 层、API 网络层、Raft 算法层、逻辑层和存储层。
常用术语
etcdctl 常用命令
全局参数
ETCD_CA_CERT="/etc/kubernetes/pki/etcd/ca.crt"
ETCD_CERT="/etc/kubernetes/pki/etcd/server.crt"
ETCD_KEY="/etc/kubernetes/pki/etcd/server.key"
HOST_1=https://xxx.xxx.xxx.xxx:2379使用示例:
ETCDCTL_API=3 etcdctl --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" \
--endpoints="${HOST_1}" endpoint status --write-out=table 常用命令
1. 键值操作
# 增 & 改
put foo bar
# 查
get foo
# 根据前缀查询
get --prefix "/demo"
# 查询所有 keys
get --prefix "" --keys-only
# 删
del foo
# 事务,多个操作合并为一个事务
txn <<<'mod("key1") > "0"
put key1 "overwrote-key1"
put key1 "created-key1"
put key2 "some extra key"
'
# 压缩
compaction 1234
# 监听
watch foo2. 集群维护
# 列出成员
member list
# 端点健康情况
endpoint health
# 端点状态
endpoint status
# 告警列表
alarm list
# 解除所有告警
alarm disarm
# 碎片整理
defrag
# 创建快照进行备份
snapshot save snapshot.db
# 快照恢复
snapshot restore
# 快照状态
snapshot statusetcd监控
重点监控指标
指标分类
-
健康状态
-
USE 方法(系统)
-
使用率
-
饱和度
-
错误
-
-
RED 方法(应用)
-
请求速率
-
错误率
-
延迟
-
| 指标分类 | 指标 | 释义 |
|---|---|---|
| 健康状态 | 实例健康状态 | etcd是一个分布式系统,由多个成员节点组成。监控etcd成员节点的状态可以帮助你了解集群中节点的健康状况,发现掉线或者异常节点。 |
| 健康状态 | 主从状态 | |
| 健康状态 | etcd leader切换统计 | 频繁的领导者变更会严重影响 etcd 的性能。这也意味着领导者不稳定,可能是由于网络连接问题或对 etcd 集群施加的过载负荷导致的。 |
| 健康状态 | 心跳 | etcd集群中的节点通过发送心跳来保持彼此之间的连接。监控丢失的心跳可以帮助你发现etcd节点之间的通信问题或者网络延迟。 |
| RED 方法 | QPS | |
| RED 方法 | 请求错误率 | 监控etcd的错误率可以帮助你发现etcd操作中的潜在问题。高错误率可能表明集群遇到了故障或其他异常情况。 |
| RED 方法 | 请求延迟 | 监控etcd的请求延迟可以帮助你了解API请求的处理时间。较高的延迟可能表明etcd正面临负载压力或性能问题。 |
| RED 方法 | 磁盘同步(WAL/DB fsync)耗时 | 高磁盘操作延迟(wal_fsync_duration_seconds或backend_commit_duration_seconds)通常表示磁盘问题。它可能会导致高请求延迟或使群集不稳定。 |
| RED 方法 | 同步延迟 | 如果集群正常运行,已提交的提案应该随着时间的推移而增加。重要的是要在集群的所有成员中监控这个指标;如果单个成员与其领导节点之间存在持续较大的滞后,这表明该成员运行缓慢或存在异常。 |
| RED 方法 | 提案失败次数 | 失败的提案通常与两个问题相关:与领导选举相关的暂时性故障或由于集群丧失法定人数而导致的较长时间的停机。 |
| RED 方法 | 快照处理时间 | etcd定期创建快照以备份数据。监控快照处理时间可以帮助你了解etcd备份的性能,确保备份任务能够及时完成。 |
| RED 方法 | watcher 数量 | 监控etcd集群当前连接到etcd的客户端数量。如果连接数过高,可能需要调整etcd的配置或者增加集群的容量。 |
| USE 方法 | CPU 使用率 | |
| USE 方法 | 内存使用量 | |
| USE 方法 | 打开文件数 | |
| USE 方法 | 存储空间使用率 | 监控etcd存储空间的使用率可以帮助你确保etcd有足够的空间存储配置数据。如果使用率接近或达到上限,可能需要考虑扩展存储容量或者清理无用的数据。 |
使用 kube-prometheus 收集 etcd 指标
http 模式(推荐)
修改--listen-metrics-urls
#- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-metrics-urls=http://127.0.0.1:2381,http://ip:2381
# 部署
helm install monitoring -n cattle-prometheus --set kubeEtcd.service.port=2381 --set kubeEtcd.service.targetPort=2381 --set prometheusOperator.admissionWebhooks.patch.image.sha=null ./https 模式
新增 etcd secret
kubectl create secret generic etcd-certs -n cattle-prometheus --from-file=/etc/kubernetes/pki/etcd/ca.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key
# 部署
helm install monitoring -n cattle-prometheus --set kubeEtcd.serviceMonitor.scheme=https --set kubeEtcd.serviceMonitor.caFile=/etc/prometheus/secrets/etcd-certs/ca.crt --set kubeEtcd.serviceMonitor.certFile=/etc/prometheus/secrets/etcd-certs/healthcheck-client.crt --set kubeEtcd.serviceMonitor.keyFile=/etc/prometheus/secrets/etcd-certs/healthcheck-client.key --set prometheus.prometheusSpec.secrets={etcd-certs} --set prometheusOperator.admissionWebhooks.patch.image.sha=null ./
大盘展示
Grafana 大盘:https://github.com/clay-wangzhi/grafana-dashboard/blob/master/etcd/etcd-dash.json
监控指标补充

收集过程详见:https://github.com/clay-wangzhi/etcd-metrics
参考 https://github.com/kstone-io/kstone 进行裁剪
Etcd 基准测试
SLI & SLO
SLO 是 SLI 要达成的目标,我们需要选择合适的 SLI,设定对应的 SLO。
| SLI | SLO | 测试方式 |
|---|---|---|
| 吞吐量:衡量etcd每秒可以处理的请求数量 | 每秒处理40,000个读取请求和20,000个写入请求 | 官方 benchmark |
| 响应时间:衡量etcd对于读取和写入请求的响应时间 | 99%的读写请求在100毫秒以内完成 | 官方 benchmark |
使用 benchmark 测试延迟和吞吐量
1. 安装golang环境
wget https://golang.google.cn/dl/go1.19.10.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.19.10.linux-amd64.tar.gz
# 配置环境变量
vim /etc/profile
export PATH=$PATH:/usr/local/go/bin
export GOPROXY=https://goproxy.cn
source /etc/profile
# 检查验证
go version2. 安装 benchmark 工具
git clone https://github.com/etcd-io/etcd.git --depth 1
cd etcd/
go install -v ./tools/benchmark
# 找到二进制文件位置
go list -f "{{.Target}}" ./tools/benchmark3. 基准测试
# 查看帮助信息
cd /root/go/bin/
./benchmark -h
# 配置环境变量
ETCD_CA_CERT="/etc/kubernetes/pki/etcd/ca.crt"
ETCD_CERT="/etc/kubernetes/pki/etcd/server.crt"
ETCD_KEY="/etc/kubernetes/pki/etcd/server.key"
HOST_1=https://xxx.xxx.xxx.xxx:2379
HOST_2=https://xxx.xxx.xxx.xxx:2379
HOST_3=https://xxx.xxx.xxx.xxx:2379
# 提前写个测试 key
YOUR_KEY=foo
ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" put $YOUR_KEY bar写测试
# write to leader
./benchmark --endpoints=${HOST_2} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --target-leader --conns=1 --clients=1 \
put --key-size=8 --sequential-keys --total=10000 --val-size=256
./benchmark --endpoints=${HOST_2} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --target-leader --conns=100 --clients=1000 \
put --key-size=8 --sequential-keys --total=100000 --val-size=256
# write to all members
./benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --conns=100 --clients=1000 \
put --key-size=8 --sequential-keys --total=100000 --val-size=256读测试
# Single connection read requests
./benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --conns=1 --clients=1 \
range $YOUR_KEY --consistency=l --total=10000
./benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --conns=1 --clients=1 \
range $YOUR_KEY --consistency=s --total=10000
# Many concurrent read requests
./benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --conns=100 --clients=1000 \
range $YOUR_KEY --consistency=l --total=100000
./benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --conns=100 --clients=1000 \
range $YOUR_KEY --consistency=s --total=100000使用 FIO 测试磁盘性能
Etcd 对内存和 CPU 消耗并不高,足够就行
一次 Etcd 请求的最小时间 = 成员节点之间的网络往返时延 + 收到数据之后进行持久化的时延。因此,Etcd 的性能主要受两方面的约束:
-
网络
-
磁盘
多节点的 Etcd 集群成员节点应该尽量部署在同一个数据中心,减少网络时延。同一数据中心内,不同节点的网络情况通常是非常好的,如果需要测试可以使用 ping 或 tcpdump 命令进行分析。
存储性能能够满足 etcd 的性能要求,有两种方法测试:
如何调优?
1. 硬盘
使用SSD固态硬盘
给定较高的磁盘优先级
# best effort, highest priority
$ sudo ionice -c2 -n0 -p `pgrep etcd`2. CPU
CPU 性能模式调整为 performance , 如何调整不成功参考:https://clay-wangzhi.com/cloudnative/troubleshooting/vm-vs-container-performance.html#cpu
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
3. 配置参数优化
开启自动压缩、修改etcd raft消息最大字节数、修改 etcd最大容量等。
参考资料:
github etcdctl doc:https://github.com/etcd-io/etcd/blob/main/etcdctl/README.md
datadog etcd 指标:https://docs.datadoghq.com/integrations/etcd/?tab=host
etcd 官方文档-tunning:https://etcd.io/docs/v3.5/tuning/
etcd 官方文档-硬件要求:https://etcd.io/docs/v3.5/op-guide/hardware/
etcd 官方文档-benchmark:https://etcd.io/docs/v3.5/benchmarks/etcd-3-demo-benchmarks/
使用fio测试etcd是否满足要求:https://www.ibm.com/cloud/blog/using-fio-to-tell-whether-your-storage-is-fast-enough-for-etcd










