
实验要求
完成对中文搜狗新闻语料库的LDA主题提取。
实验内容
一、训练关键词提取算法
(1)加载已有的文档数据集。

为了解决编码错误,将编码改为GB18030:

能读取的文件数量从17678,增加到了17910。
打印文件内容信息,检查是否正确。

(2)加载停用词表。

(3)对数据集中的文档进行分词。并根据停用词表,过滤干扰词。
1.去除文本中的日期和时间
Demo1:

Demo2:
由于还需去除文本中的数字和英文字符,因此对于2022年1月1日这种字符串,去除“年”、“月”、“日”、“时”、“分”、“秒”即可,即将这些字符加入停用词中。而后发现原有停用词已包含这些字符,因此不需要额外处理。

2.去除文本中的数字和英文字符
Demo:

3.去除停用词

\n没有去除。寻找原因:1.停用词中没有\n,因此先打印停用词列表。

找到问题。如果不想让转义字符生效,需要显示字符串原来的意思,这就要用r和R来定义原始字符串。用了r后,还是存在问题。
使用另一种解决方案,问题得到解决。

最终版本:

其中,当len(words) =0时,不添加到列表。
(4)分词后单词的可视化
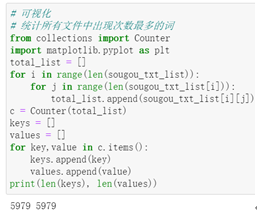

可以发现,单个词语和市场出现频率很高。
(5)根据数据集训练算法。

发现词频过高的词语会影响主题判断,因此进行过滤。

pyLDAvis是一个可以帮助用户理解语料库中主题分布的一个可视化工具。 pyLDAvis从训练好的LDA主题模型中提取信息,以通Web的交互式形式将主题分布做可视化的展示。

解决:pip install pyLDAvis==2.1.2
基于TF-IDF的建模:

基于计数的建模:

验证:

预期:
C000007 汽车
C000008 财经
C000010 IT
C000013 健康
C000014 体育
C000016 旅游
C000020 教育
C000022 招聘
C000023 文化
C000024 军事
不太符合。。。后期可以改进。
二、对新文档进行关键词提取
(1)对新文档进行分词。
(2)根据停用词表,过滤干扰词。

(3)根据训练好的算法提取关键词。










