文章目录
- 一:代码
- 二:结果如下(部分例子)
- 1.输入天气之子
- 2.输入百变小樱魔法卡
- 3.独立日
这里是爬取豆瓣视频信息,用pyquery库(jquery的python库)。
一:代码
from urllib.request import quote
from pyquery import PyQuery as pq
import requests
import pandas as pd
def get_text_page(movie_name):
'''
函数功能:获得指定电影名的源代码
参数:电影名
返回值:电影名结果的源代码
'''
url = 'https://www.douban.com/search?q=' + movie_name
headers = {
'Host' : 'www.douban.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
}
r = requests.get(url,headers = headers,timeout=5)
return r.text
def get_last_url(this_text):
'''
函数功能:根据指定的源代码得到最终的网页地址
参数:搜索结果源代码
返回值:最终的网页地址
'''
doc = pq(this_text)
lis = doc('.title a').items()
k = 0
this_str = ''
for i in lis:
# print('豆瓣搜索结果为:{0}'.format(i.text()))
# print('地址为:{0}'.format(i.attr.href))
# print('\n')
if k == 0:
this_str = i.attr.href
k += 1
return this_str
def the_last_page(this_url):
'''
函数功能:获得最终电影网页的源代码
参数:最终的地址
返回值:最终电影网页的源代码
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
}
r = requests.get(this_url,headers = headers,timeout=20)
return r.text
def the_last_text(this_text,movie_name):
'''
函数功能:获得每一项的数据
参数:爬取页面的源代码
返回值:返回空
'''
doc = pq(this_text)
# 获取标题
title = doc('#content h1').text()
# 获取海报
photo = doc('.nbgnbg img')
photo_url = photo.attr.src
r = requests.get(photo_url)
with open('{m}.jpg'.format(m = movie_name),'wb') as f:
f.write(r.content)
# 电影信息
message = doc('#info').text()
# 豆瓣评分
grade = doc('#interest_sectl').text()
# 剧情
things = doc('.related-info').text()
with open('{0}.txt'.format(movie_name),'w+') as f:
try:
f.writelines([title,'\n','\n\n',message,'\n\n',grade,'\n\n',things])
except:
f.writelines([title,'\n','\n\n',message,'\n\n',grade])
# 演员
# 演员名
name = []
person_name = doc('.info').items()
for i in person_name:
name.append(i.text())
# 演员图片地址
person_photo = doc('#celebrities')
j = 0
for i in person_photo .find('.avatar').items():
m = i.attr('style')
person_download_url = m[m.find('(') + 1:m.find(')')]
# 下载演员地址
r = requests.get(person_download_url)
try:
with open('{name}.jpg'.format(name = name[j]),'wb') as f:
f.write(r.content)
except:
continue
j += 1
def lookUrl(this_text,my_str):
'''
函数功能:获得观看链接
参数:爬取页面的源代码
返回值:返回空
'''
doc = pq(this_text)
all_url = doc('.bs li a').items()
movie_f = []
movie_url = []
for i in all_url:
movie_f.append(i.text())
movie_url.append(i.attr.href)
dataframe = pd.DataFrame({'观看平台':movie_f,'观看地址':movie_url})
dataframe.to_csv("{movie_name}的观看地址.csv".format(movie_name = my_str),index=False,encoding = 'utf_8_sig',sep=',')
def main():
name = input('')
my_str = name
movie_name = quote(my_str)
page_text = get_text_page(movie_name) # 得指定电影名的源代码
last_url = get_last_url(page_text) # 根据指定的源代码得到最终的网页地址
page_text2 = the_last_page(last_url) # 获得最终电影网页的源代码
the_last_text(page_text2,my_str) # 获得每一项的数据
lookUrl(page_text2,my_str) # 得到并处理观看链接
main()二:结果如下(部分例子)
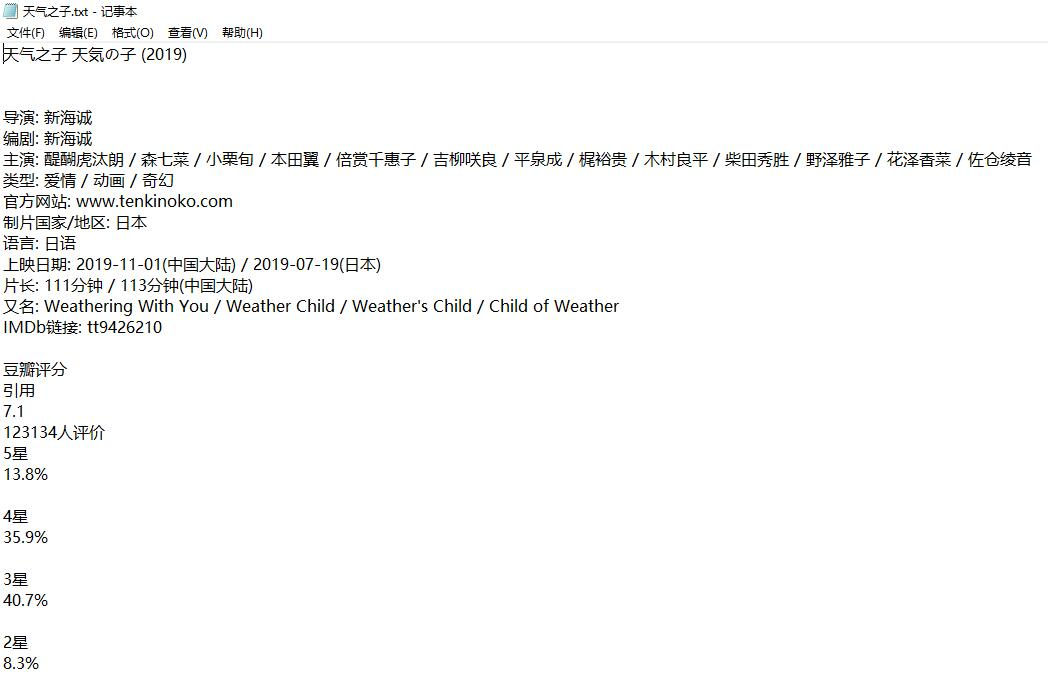
1.输入天气之子

2.输入百变小樱魔法卡
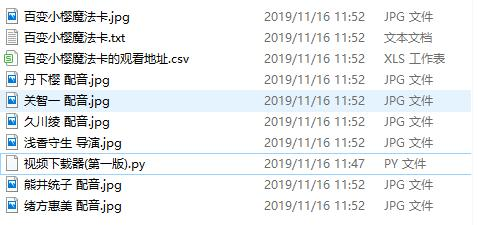
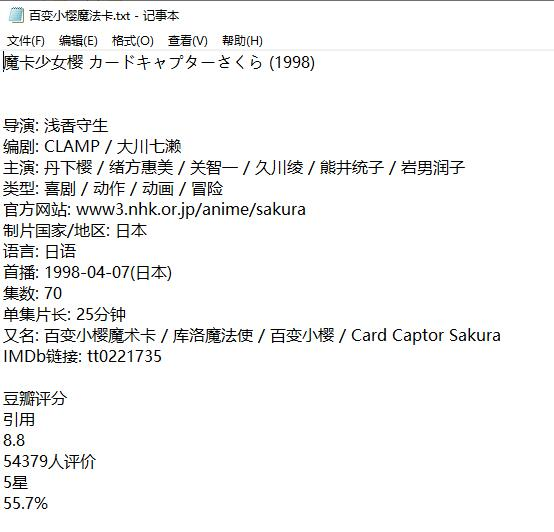

必须是已经上映的电影才有观看地址
3.独立日