
MedDialog: Large-scale Medical Dialogue Datasets
数据集
会议:EMNLP2020
任务:医疗对话生成
动机:现有的医疗对话数据集规模太小,涵盖范围不够广,或偏向某种确定的疾病。
贡献:
- 提出了目前最大规模的医疗对话数据集MedDialog,有中文和英文数据集。
- 在中文数据及上预训练了几个对话生成模型,评估其性能。
- 通过人工评估和自动评估,研究表明在MedDialog-CN上预训练的模型通过迁移学习,应用于低资源对话生成任务上,可以显著提升其性能。
数据集介绍
- 中文数据集覆盖了172种疾病。每个对话以对医疗状况和病史的描述(包括疾病现状、病程、过敏症、药物治疗、既往疾病)开始,然后进行医患对话,最后医生提出诊断和治疗意见。
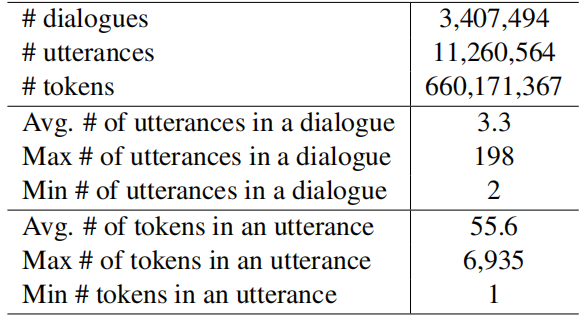
- 英文数据集覆盖了96种疾病。每个对话包括两部分,第一部分是对病情的描述,第二部分是多轮对话。这些咨询涵盖了51类社区,包括糖尿病、老年问题、疼痛管理等。2008-2020年。
- 优点:
规模大,覆盖的疾病多。
MedDialog-EN的患者来自世界各地,具有不同的国籍、伦理、年龄、性别、职业、教育、收入等方面。

- 和其他数据集的对比。
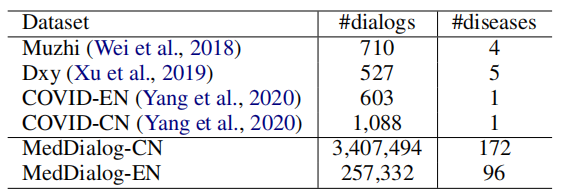
- 数据集的优点。
- 规模大。
- 各种各样的病人。
方法
-
在中文医疗对话数据集上预训练了几种对话生成模型,包括Transformer,GPT,BERT-GPT,并比较了他们的性能。结果表明,用MedDialog训练的模型能够生成临床正确和类人的医学对话。我们还研究了在MedDialog上训练的模型对低资源医疗对话生成任务的可转移性。结果表明,通过对MedDialog预训练的模型进行迁移学习,可以大大提高小数据集下医疗对话生成任务的性能,如人工评估和自动评估所示。
首先在比MedDialog更大规模的通用对话数据集上预训练Transformer和GPT。
实验
-
在中文数据集上的实验。
8:1:1,以dialogue划分数据集,编码嵌入以汉字为单位,不做分词。
-
模型。
-
BERT-GPT:BERT和GPT都是12层Transformer,隐藏状态大小是768,SGD,输入序列最大长度是400,输出序列最大是100。
在一个大规模的NLP中文语料库做预训练。nlp_chinese_corpus
-
GPT: DialoGPT-small,10层,embedding size=768,context size=300,多头注意力:12个head。Adam。
在两个中文对话语料库上做预训练。chinese_chat_bot_corpus 500k-Chinese-Dialog
-
-
实验及结果。
-
自动评估。三方面:机器翻译指标、多样性指标、困惑度。
-
BERT-GPT的perplexity更低。因为它在一个大规模中文语料库上做了预训练然后再在MedDialog上做微调。在机器翻译指标上评估结果低于Transformer。在多样性指标上,效果基本相同。
-
-
迁移到其他数据集。
在MedDialog预训练后,在中文COVID-19Dialog上微调后的结果得到提升。
- 模型评估
- 自动评估。三方面:机器翻译指标、多样性指标、困惑度。
- 人工评估。随机选择100个对话例子,让5名本科生和研究生从信息量、相关性和人类相似性方面对生成的回答进行评分。
- 实验结果
- 预训练后的Transformer自动评估指标全面提升。GPT和BERT-GPT相对不如。
- 模型评估
成的回答进行评分。
- 实验结果
- 预训练后的Transformer自动评估指标全面提升。GPT和BERT-GPT相对不如。