
§01 引 言
目标检测是计算机视觉和数字图像处理的一大热门方向,其应用广泛,在自动驾驶、视频监控、工业检测、故障分析与处理等诸多领域都有其身影,通过对计算机视觉的研究也大大减小了人力资源的消耗以及人工检测的错误率。因此,目标检测作为计算机视觉中最基本的任务自然也就成为了近年来研究的热点。
从 2006年以来, Bengio、Hinton等人引领了深度神经网络的浪潮,大量相关论文被发表。最早出现的卷积神经网络是 LeNet[1]网络,这个网络虽然很小,却包含了卷积网络所有的基本模块,即卷积层、池化层、全连接层,是其他深度学习模型的基础。但深度神经网络得到人们的广泛关注是在 2012年,在这一年 Hinton课题组首次参加 ImageNet图像识别比赛,并通过构建的 AlexNet[2] CNN网络取得冠军。 2015年, He等人通过构建残差网络 (ResidualNetwork, ResNet[3])使得网络的深度被大幅扩展,甚至到达了 1000层,由此深度学习取得了迅猛的发展。
深度学习是利用多层计算模型来学习数据的特征,即数据的抽象表示,目前该技术已广泛应用于计算机视觉领域等模式识别的问题上。目标检测既是计算机视觉的基础任务之一,同时也是视频监控技术的基础任务。由于图像中的目标姿态、色彩、亮度、饱和度、分辨率、天气和场景的多变性和复杂性,对目标的检测、跟踪、动作识别、行为表述等任务在今天依旧是一项非常具有挑战性的课题,存在很大的提升潜力和发展空间。但是,从目前的理论研究和工程实现来看,基于卷积神经网络的目标检测算法相较于传统算法,已经在各方面取得了非常大的提升,几乎已经完全代替了传统的目标检测算法。
§02 传统算法
传统的目标检测算法一般分为三个阶段,即区域选择、特征提取和分类。下面对三个阶段分别进行介绍和分析。
- 区域选择:对目标位置进行定位。设置不同的尺度和长宽比,然后采用滑动窗口的策略对整幅图像进行遍历。这种穷举法的缺点显而易见,即产生了大量冗余窗口,时间复杂度极高,同时大大影响了后续的特征提取和分类预测的速度和性能。
- 特征提取:通常采用人工提取的策略,即手工设计特征提取算法对目标进行识别。由于场景多变性和目标姿态多样性,甚至光照变化引起的图像色彩和饱和度的变化都会使得人工设计的特征提取算法很难具有较强的泛用性,并且设计此算法也需要具有丰富的工程经验。此阶段常用的特征有 SIFT[4]、HOG[5]等。
- 分类:根据特征提取得到的特征对目标进行分类,分类器主要有 SVM、 AdaBoost等。分类结果的好坏直接决定于第二步提取特征的准确和置信度。
综上所述,传统检测算法滑动窗口策略的时间复杂度较高,特征提取器鲁棒性和泛用性不够强,因而其不能满足当下目标检测的要求。
§03 深度学习
传统的特征提取是采用手工设计特征提取器的方法,一般基于一些统计规律和设计者本人的先验知识,不能完全提取出原始图像的信息,因而具有较弱的泛化性能和鲁棒性。卷积神经网络通过学习的方法来自动提取图像更深层次的结构和特征,是一类专门用来处理图像数据的网络结构。卷积网络增加了局部感受野、稀疏权重和参数共享的概念,使得其具有一定的平移和尺度的不变性,更加适合图像这种二维结构的数据的学习。下面将对近年来提出的经典卷积模型进行简要介绍。
3.1 LeNet
LeNet于 20世纪九十年代由 Yan LeCun提出,主要用来进行手写字符的识别和分类,它的实现确立了卷积网络的基本结构——卷积层、池化层、激活函数层和全连接层。由于提出年代久远,当时计算机硬件性能较低,并且缺乏大规模的训练数据,因此 LeNet网络在处理复杂问题时的效果并不理想。
3.2AlexNet
AlexNet[2]是 2012年 ImageNet竞赛冠军获得者 Hinton和他的学生 Alex Krizhevsky设计的,包含了几个比较新的技术点,也首次在 CNN中成功应用了 ReLU、Dropout和 LRN,同时使用了 GPU进行算法加速。 AlexNet把 CNN的基本原理应用到了很宽很深的网络中,其主要用到的新技术总结如下:
(1)使用 ReLU代替 Sigmoid作为 CNN的激活函数,解决了 Sigmoid在网络较深时的梯度消失问题。
(2)训练时使用 Dropout机制随机忽略一部分神经元,以及数据增强 (data augmentation)机制,避免了模型过拟合,提高模型的泛化能力。
(3)采用最大池化 (max pooling),避免平均池化 (average pooling)的模糊化效果,提升了特征的丰富性。
(4)提出 LRN层,对局部神经元的活动创建竞争机制,增强了模型的泛化能力。
(5)使用 CUDA加速深度卷积网络的训练,利用 GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算,极大的减小了模型的训练周期。
3.3VGGNet
VGGNet[6]由牛津大学计算机视觉组合和 Google DeepMind公司研究员于 2014年合作研发的卷积网络,获得了 ILSVRC2014年比赛的亚军和定位项目的冠军。该模型全部使用 3*3卷积核来进行特征提取,并证明了模型深度越深、参数越多,其提取特征的能力越强,效果越好。
3.4 ResNet
何凯明等人于 2015年提出 ResNet[3]残差网络,解决了卷积网络随着深度的增加会越来越慢难以训练的问题。当网络的深度逐渐变大时,梯度消失现象愈加明显,计算复杂度也快速上升,残差学习则有效地解决了这些问题。残差模型的核心思想是引入“ shortcut”实现卷积层的跳跃式连接 (skip connection),模型如图 1。

▲ 图3.4.1 残差模型
左图是普通的卷积块,右图是添加了 shortcut的残差块。
3.5 Inception
2014年 Christian等提出了 Inception[7-8]系列。
(1)Inception-v1:提出卷积核并行合并 (Bottleneck Layer),使得在同一层
可以提取不同的特征。网络中每一层都能学习到“稀疏”或“不稀疏”的特征,既增加了网络的宽度,也增加了网络对尺度的适应性。同时,通过 deep concat在每个 block后合成特征,获得非线性属性。按照这样的结构来增加网络的深度,虽然可以提升性能,但是还面临计算量大(参数多)的问题。
(2)Inception-v2:使用 BN层,将每一层的输出都规范化到一个 N(0,1)的正态分布,同时使用 1*n和 n*1这种非对称的卷积来代替 n*n的对称卷积,既降低网络的参数,又增加了网络的深度。
(3)Inception-v3:采用并行的降维结构。
(4)Inception-v4:将原来卷积、池化的顺次连接(网络的前几层)替换为 stem模块,来获得更深的网络结构。
(5)Inception-ResNet-v2:结合了 Inception模块可以在同一层上获得稀疏或非稀疏的特征和 ResNet模块既可以加速训练,还可以防止梯度弥散两者的优势。
最终, Inception系列网络对图像识别的错误率对比如表 1。表 1 Inception系列模型性能对比 [8]
3.6其他卷积网络
(1)DenseNet[9]使用前馈和反馈的形式将每一层连接到另一层,建立了层与层之间的稠密连接,可以有效环节梯度消失、增强特征传播和重用。
(2)Andrew于 2017年提出 MobileNet-v1[10]模型,大幅减小了模型参数和运算量。
(3)Li于 2019年提出 SKNet[11]模型,允许每个神经元根据输入信息的多个尺度来自适应地调整其接受区域的大小。

▲ 图3.6.1 Inception系列模型性能对比
§04 二阶段目标检测
4.1 R-CNN
R-CNN的全称是 Region-CNN,是第一个成功将深度学习应用到目标检测上的算法。 R-CNN在提取特征时,将传统的特征 (如 SIFT、HOG特征等 )换成了深度卷积网络提取的特征,解决了窗口冗余问题,提高了网络对外抗干扰能力。但模型需要生成 2000个候选区域,较为耗时,并且图像的裁剪或拉伸会导致图像信息的丢失 [13]。R-CNN框架结构如图 2。

▲ 图4.1.1 R-CNN框架结构
4.2 SPPNet
``SPP-Net``的主要思想是输入整张图像,提取出整张图像的特征图,然后利用空间关系从整张图像的特征图中,在 ``spatialpyramid poolinglayer``提取各个 region ``proposal``的特征。相比于 R-CNN提取 2000个 ``proposal``,SPP-net只需要将整个图扔进去获取特征,这样操作速度提升了 100倍左右 [14]。
<span id=987003></span>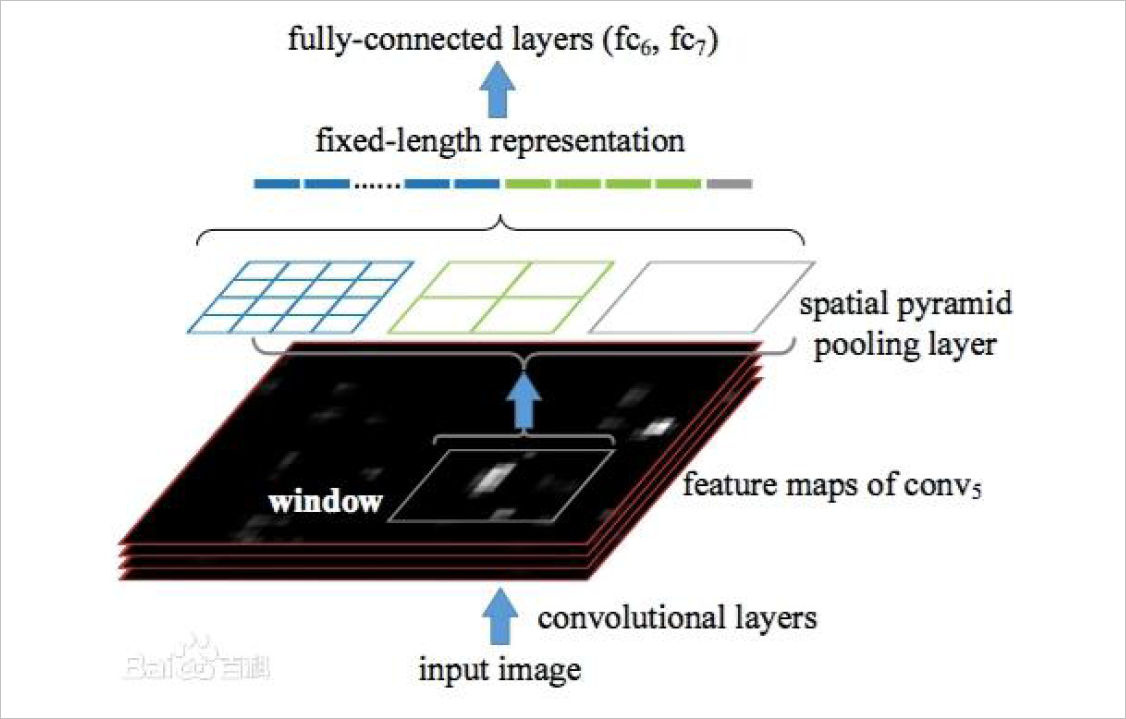<center>``▲ 图4.2.1 SPP-NET框架结构``</center>
## <font color=#7a37ab>4.3 Fast R-CNN </font>
``Fast R-CNN[15]``于 ``2015``年由 ``Girshick``等提出,主要有两大贡献:
(``1``)实现大部分 ``end-to-end``训练( ``proposal``阶段除外):所有的特征都暂存在显存中,就不需要额外的磁盘空。
(``2``)提出 ``ROI``(``Region of Interest``)池化层,相当于单层 ``SPPLayer``。不同的是 ``SPP``是 ``pooling``成多个固定尺度, ``ROI``只 ``pooling``到单个固定的尺度,如图 ``4``。
<span id=987004></span>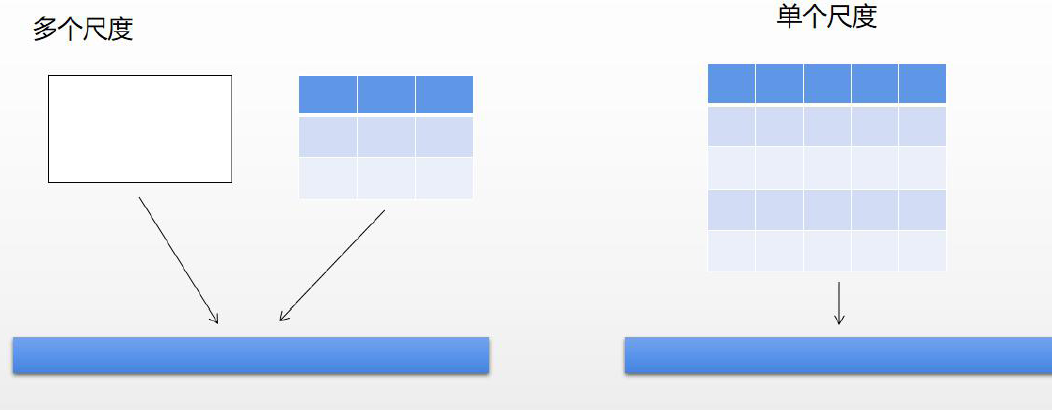<center>``▲ 图4.3.1 Fast R-CNN框架``</center>
Fast R-CNN使用了多任务损失,使得训练速度在同等条件下比 R-CNN快 8倍。
## <font color=#7a37ab>4.4 FasterR-CNN </font>
``Faster R-CNN[16]``于 ``2016``年由 ``Ren``等提出。在结构上, ``Faster R-CNN``已经将特征抽取、 ``proposal``提取、 ``boundingboxregression``、``classification``都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显,真正实现了端到端,其框架结构如图 ``5``。
<span id=987005></span>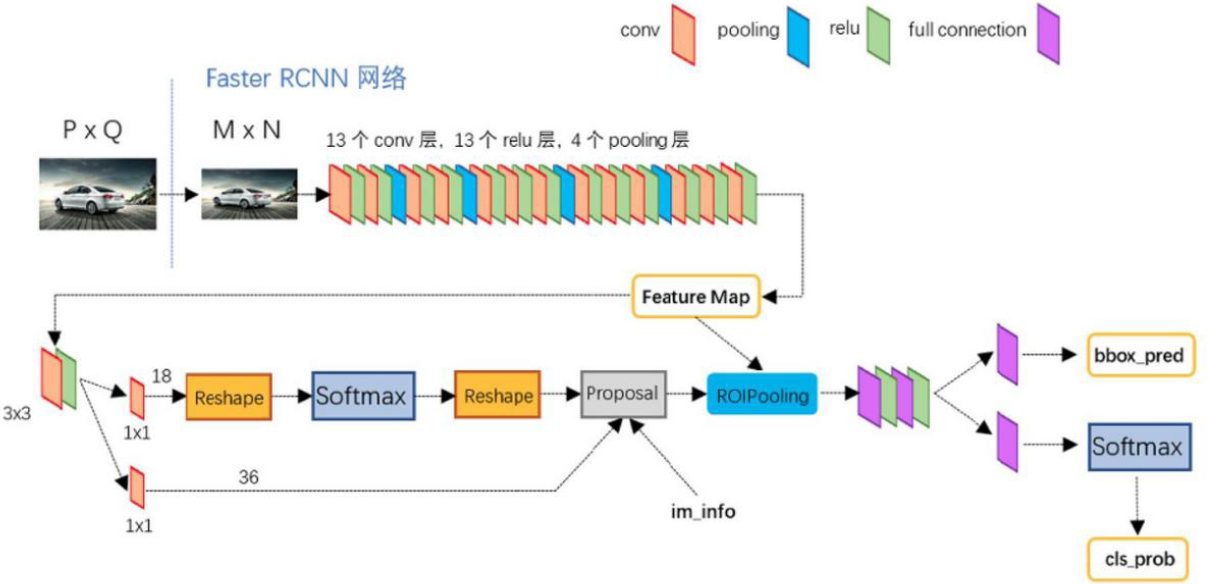<center>``▲ 图4.4.1 Fast R-CNN框架``</center>
``Faster R-CNN``的不足之处在于 ``ROI``池化层生成的每个特征向量需要经过多个全连接层,这大大增加了计算复杂度和时间复杂度,并且其对小目标检测的效果不是很好。
## <font color=#7a37ab>4.5 Mask R-CNN </font>
``MaskR-CNN[17]``由 He等人于 2017年提出,结合了 Faster R-CNN和 FCN的思想,在一个网络中同时做目标检测和实例分割。 ``MaskR-CNN``的多尺度的特征提取能力得到加强,对小目标物体识别的正确率有了改进,但并没有解决时间复杂度的问题,计算起来不能满足实时监测应用的要求。
## <font color=#7a37ab>4.6TridentNet </font>
``TridentNet[18]``由 ``Li``等人于 ``2019``年提出。该网络首次提出感受野对目标检测任务中不同 ``scale``大小物体的影响,提出了适应于多尺度的目标检测框架。同时,使用参数共享的方法,提出了训练时 ``3``个 ``branch``,测试时只使用其中一个 ``branch``,这样保证推断时不会有额外参数和计算量的增加。整个模型成功地解决了目标检测中尺度不变的问题,但是并没有提高检测速度。其框架结构如图 ``6``。
<span id=987006></span>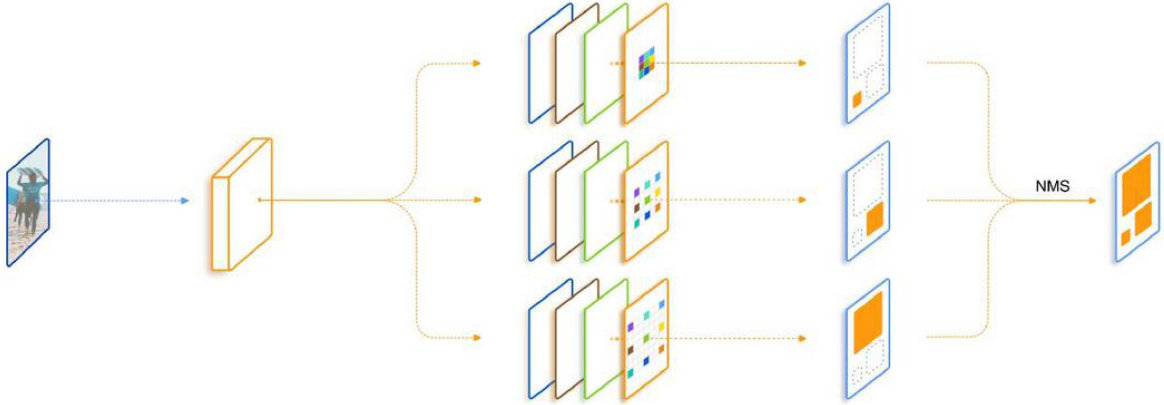<center>``▲ 图4.6.1 TridentNet框架结构``</center>
# <center><font face=黑体 color=slateblue size=6>§<u>05</u> <font color=red>基</font>于回归算法</font></center>
---
## <font color=#7a37ab>5.1YOLO</font>
基于回归的目标检测算法省略了候选区域的生成阶段,直接将特这提取、目标分类以及目标回归在同一个卷积神经网络中实现,真正实现了端到端 ``(end-to-end)``。``YOLO``将对象检测重新定义为一个回归问题。它将单个卷积神经网络应用于整个图像,将图像分成网格,并预测每个网格的类概率和边界框。然后,对于每个网格,网络都会预测一个边界框和与每个类别(比如汽车,行人,交通信号灯等)相对应的概率。
``YOLO``算法还可以预测边界框中存在对象的概率。如果一个对象的中心落在一个网格单元中,则该网格单元负责检测该对象。每个网格中将有多个边界框。在训练时,我们希望每个对象只有一个边界框。因此,我们根据哪个 ``Box``与 ``ground truthbox``的重叠度最高,从而分配一个 ``Box``来负责预测对象。最后,我们对每个类的对象应用一个称为 “非最大抑制 ”的方法来过滤出 “置信度 ”小于阈值的边界框,为我们提供了图像预测。
``YOLO``系列目前更新到 ``YOLOv5``共五个版本。 ``2016``年, ``Redmon``等人提出 ``YOLOv1[19]``,将目标检测问题看成了回归问题的求解,检测速度很快,能够做到实时监测,但对小目标识别效果不好; ``2017``年,提出 ``YOLOv2[20]``,使用了 ``Batch Normalization``,解决了有饱和非线性模型的收敛困难问题,同时使用 ``anchor box``和卷积进行预测; ``2018``年,提出 ``YOLOv3``,采用 ``FPN``架构,提高了对小目标的检测效果; ``2020``年,提出 ``YOLOv4[21]``,加入普遍使用的算法,如残差连接、自对抗训练等,网络性能进一步提升;同年提出 ``YOLOv5``,速度非常快,有非常轻量级的模型大小,同时又在准确度方面又与 ``YOLOv4``基准相当。
## <font color=#7a37ab>5.2其他算法</font>
* <b>SSD[22]</b>:2016年 Liu等人提出 SSD算法。该算法生成多尺度 defaultbox,开创了应用多尺度的特征图进行目标检测的先河。但 SSD的候选框数量较多,因此训练时较慢。
* <b>RetinaNet[23]</b>:2017年 Lin等人提出来 RetinaNet算法,通过重塑标准的交叉熵损失函数,引入了名为“聚焦”的新损失函数。此损失函数降低了易分类样本的权重,以便检测器在训练过程中将更多的注意力放在分类困难的样本。
* <b>EfficienDet[24]</b>:2019年 Tan等人提出了 EfficienDet算法,兼顾检测速度和精度,同时引入联合尺度缩放的方法,快速进行多尺度特征融合将主干网络、特征网络深度、宽度和分辨率进行统一缩放,以达到最优效果。
# <center><font face=黑体 color=slateblue size=6>§<u>06</u> <font color=red>总</font>结与展望</font></center>
---
<font color=gray size=5>本</font>文结合国内外研究现状,总结了目标检测算法的发展情况,重点对近年来基于深度学习方法和卷积网络的目标检测算法进行了介绍和分析,并对相关网络的优缺点进行简要介绍。本文认为未来的研究方向应该有以下几点:
(1)在数据层面,应该扩大数据集,开发具有更多类别的大规模数据集,可通过数据增强方法扩充,以便于网络能够学习更深的特征而不至于过拟合;
(2)在网络层面,应该研究轻便式模型,避免网络的冗余,提高计算速度,减小时间复杂度;
(3)在目标检测层面,应该可以通过检测器定位并识别之前从未遇到过的类别,增强网络的泛用性。
## <font color=#7a37ab>参考文献</font>
[1] LeCun Y, Bottou L, Bengio Y, et al. Gradient-based Learning Applied to DocumentRecognition[J].Proceedings of theIEEE,1998,86(11):2278-2324.
[2] Krizhevsky A, Sutskever I, Hinton G E. Imagenet Classification with Deep Convolutional Neural Networks[J]. Communications of theACM,2017,60(6): 84-90.
[3] HeK,Zhang X,Ren S,etal. Deep ResidualLearning for Image Recognition[J]. IEEE,2016.
[4] D. Lowe. Distinctiveimagefeaturesfromscale-invariantkeypoints. IJCV,2004.
[5] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR,2005.
[6] Simonyan K,Zisserman A. Very Deep Convolutional Networks for Large-scale Image Recognition[J].ArXiv PreprintArXiv:1409.1556,2014.
[7] Szegedy C, Liu W, Jia Y, et al. Going Deeper with Convolutions[ C] //Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9.
[8] Szegedy C , Liu W , Jia Y , et al. Going Deeper with Convolutions[J]. IEEE ComputerSociety,2014.
[9] Huang G,Liu Z,Van Der Maaten L,et al. Densely Connected Convolutional Networks[C]//Proceedings of the IEEE Conference on Computer Vision and PatternRecognition,2017:4700-4708.
[10]HowardAG,Zhu M,Chen B,et al. Mobilenets:Efficient ConvolutionalNeural Networks forMobileVisionApplications[J].ArXivPreprintArXiv:1704.04861, 2017.
[11]Li X,WangW,HuX,et al. Selective KernelNetworks[C]//Proceedings of the IEEEConference onComputerVisionandPattern Recognition,2019:510-519.
[12]百度图片 .https://image.baidu.com/search
[13]Donahue J,JiaY,Vinyals O,et al. Decaf:ADeep ConvolutionalActivation Feature for Generic Visual Recognition[ C] //International Conference on Machine Learning,2014,50(1): 647-655.
[14]He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015,37(9):1904-16.
[15]Girshick R. Fast R-cnn[C]//Proceedings of the IEEE International Conference on
ComputerVision,2015:1440-1448.
[16]Ren S, He K, Girshick R, et al. Faster R-cnn: Towards Real-time Object Detection with Region Proposal Networks[ J]. IEEE Transactions on Pattern AnalysisandMachine Intelligence,2016,39(6): 1137-1149.
[17]He K,Gkioxari G,Dollár P,et al. Mask R-cnn[C]//Proceedings of the IEEE
7参考文献
InternationalConference onComputerVision,2017:2961-2969. [18]LiY,ChenY,WangN,et al. Scale-awareTrident Networks for Object Detection
[C]//Proceedings of the IEEE International Conference on Computer Vision, 2019:6054-6063.
[19]RedmonJ,Divvala S,Girshick R,etal.YouOnly Look Once:Unified,Real-time Object Detection[C]//Proceedings of the IEEE Conference on ComputerVision andPattern Recognition,2016:779-788.
[20]RedmonJ,FarhadiA.YOLO9000:Better,Faster,Stronger[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 7263-7271.
[21]BochkovskiyA,WangCY,Liao HYM.YOLOv4:Optimal Speed andAccuracy ofObject Detection[J].ArXivPreprintArXiv:2004.10934,2020. [22]LiuW,Anguelov D,Erhan D,etal. Ssd:Single ShotMultibox Detector[C] //EuropeanConference onComputerVision. Springer,Cham,2016:21-37.、
[23]LinTY,Goyal P,Girshick R,et al. Focal Loss for Dense Object Detection[C] //Proceedings of the IEEE International Conference on Computer Vision, 2017: 2980-2988.
[24]TanM,Le QV. Efficientnet:RethinkingModel Scaling for Convolutional Neural Networks[J].ArXiv PreprintArXiv:1905.11946,2019.
<span id=999000></span>
---
<font face=宋体 color=gray>**● 相关图表链接:**</font>
* [图3.4.1 残差模型](#987000)
* [图3.6.1 Inception系列模型性能对比](#987001)
* [图4.1.1 R-CNN框架结构](#987002)
* [图4.2.1 SPP-NET框架结构](#987003)
* [图4.3.1 Fast R-CNN框架](#987004)
* [图4.4.1 Fast R-CNN框架](#987005)
* [图4.6.1 TridentNet框架结构](#987006)










