1.CPU多核并发缓存架构剖析

这张图是早期计算机硬件CPU多核并发的缓存架构图,简单解释一下这张图的意思。
程序大家都知道是安装在硬盘中的,当我们的计算机要启动程序的时候,会先从硬盘中将程序加载到内存中去也就是加载到内存条上去。早期的CPU是直接和内存进行交互的,中间是没有什么CPU缓存的,大家都知道CPU和内存的发展计算机诞生这么多年来,CPU的性能增长还是比较快的,早些年有个摩尔定律(每隔18个月CPU的运算速度至少要翻一倍),但是主内存这么多年来就是个弟弟,运算速度或者说读写速度变化并不大,所以现在CPU和主内存之间交互速度相差简直天壤之别,如果现在我们的计算机的CPU还直接和主内存直接交互就会严重拖夸,限制整个计算机的性能。
现在的计算机CPU和主内存之间会有一个高速缓存,也就是图中的CPU寄存器,CPU缓存,只不过是分了几级,这个高速缓存其实是能显示的,打开任务管理器看到下图!!!

右下角有个L1、L2、L3这几级缓存就是CPU的高速缓存,只是这几级缓存空间并不大,这几级缓存性能非常高,性能高价格肯定贵,所以这些空间也不会特别大,一般也就是把CPU正在运行的内存数据放在这几级CPU缓存中,其他没有运行的数据还是放在主内存中存放着,那么把常用的数据加载到CPU的高速缓存 ,CPU就可以直接和高速缓存直接交互,这是我们现在计算机的架构!!!
2.JAVA线程内存模型底层实现原理

这是JAVA内存内存模型-JMM,这里说到JAVA内存模型这个概念一定要默认加上JAVA线程内存模型,记得加上线程,这样才好和JAVA的JVM内存模型区分开来,不然难免会搞混淆。
我们来看看JMM线程内存模型到底是个啥玩意!,这个JMM和我们的计算机的CPU缓存模型很类似。是基于CPU高速缓存模型来建立起来的。
在内存中有个共享变量,在主内存中,当我们的线程A要使用,线程B使用的时候,不是直接操作主内存中的共享变量,而是将主内存中的共享变量CP到自己线程中的工作内存中存放着,那我们工作线程A、B实际操作的值是直接操作自己工作内存中的变量直接交互,而不是直接操作主内存中的共享变量这里线程中的工作内存和CPU高速缓存很类似,线程执行肯定就是CPU在执行,CPU中有一块高速缓存,这张图就描述了多线程并行的时候的内存模型,这里我们结合一下代码看看!!!
public class Test {
private static boolean initFlag=false;
public static void main(String[] args) throws InterruptedException {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("waiting data ...");//等待数据
while (!initFlag){
}
System.out.println("--------------succss");//成功
}
}).start();
Thread.sleep(2000);
new Thread(new Runnable() {
@Override
public void run() {
prepareData();
}
}).start();
}
public static void prepareData(){
System.out.println("prepareing data ...");//准备数据
initFlag=true;
}
}简单说明一下这个程序的意图,首先看到代码里有一个公共变量initFlag=false,
main方法中开启第一个线程,这个线程会检测initFlag,为true时结束死循环,执行代码System.out.println("--------------succss");
那么在initFlag为false时这行代码System.out.println("--------------succss");是永远不会执行的,
往下看,会有一个线程休眠2S时间,防止下面的的线程先抢占CPU把initFlag的值变成true影响本次代码测试的目的,再往下看,会开启新的线程,这个线程会在第一个线程执行的后面在执行,这个线程的目的就是改变initFlag的值为true,那么理论上这些代码执行的逻辑就是启动第一个线程输出waiting data …,然后第一个线程会等待initFlag的值变为true时结束死循环输出--------------succss,
那么结合代码 “理论上” 输出结果如下
输出waiting data ...
进入死循环
主线程main休眠2s
开启新的线程调用prepareData方法
输出prepareing data ...
修改initFlag的值true
然后第一个线程while (!initFlag)这里会检测到initFlag的值为true取反结束死循环
输出--------------succss
那么我们启动代码看看输出结果

这里的程序还没执行完,证明while (!initFlag)死循环还在执行,违背了我们的理论不是么,当然,这里的底层实现不是我们明面上看到的代码执行那样,图中打印出waiting data …,停顿2S后有输出prepareing data …,然后打死不输出--------------succss那么这是为什么,不要慌,看一下JMM线程内存模型,是否有种恍然大悟的感觉;
结合JMM图+上面的测试代码分析一下
我们初始化的initFlag变量赋的值是存放在主内存中的,我们的第一个线程执行的时候while (!initFlag)中的initFlag的值引用的是自己线程中工作内存的共享变量副本,那么这里引用工作内存的共享变量initFlag的值为false,这个线程在打印出waiting data …后进入while 死循环,这时主线程还在继续执行,执行到休眠代码2S休眠后。开启新的线程,那么这个新的线程调用的prepareData方法中也引用了initFlag这个变量,这个新的线程中的prepareData方法中引用的initFlag这个变量也是存放在这个新线程的工作内存中的,这个prepareData方法中的initFlag=true;修改的并不是主内存中的initFlag的值,而是修改的是线程自己的工作内存中的共享变量initFlag的值,当这个线程执行完毕后会把initFlag改变后的值同步到主内存中的initFlag共享变量,第二个线程执行完毕后主内存中的initFlag变量的值确实是为true,但是第一个线程while 循环使用的值还是自己工作内存中的initFlag共享变量,这个变量的值并未受到第二个线程的修改值同步到主内存而改变,这个线程是感知不到的,所以还会一直卡在while 死循环中,那么这么解释的话也就符合我们程序的输出结果了 ,也充分验证了我们的JMM内存模型图。
那么我们怎么样才能让我们的这个程序像我们想象的那样执行呢?
诶!!!这里有个概念,保证线程的可见性,那么就会想到volatile这个关键字
那么我们就在initFlag变量前面加上一个volatile关键字修饰这个变量,让这个变量内存可见,那么我们再启程序

诶!!!这就符合我们的逻辑想法了,确实是的。
这里解释一下volatile到底起到什么作用,就是在并发编程多线程编程情况下多个线程操作同一个变量,其他线程能够感知到,这就意味着结合代码第二个线程在调用prepareData修改initFlag变量时,第一个线程能够立马感知到,说白点这个volatile就是保证共享变量在多线程情况下的可见性!那么想要知道底层的操作原理就要知道JMM数据原子操的概念,
- read(读取):从主内存读取数据
- load(载入):将主内存读取到的数据写入线程的工作内存
- use(使用):从工作内存读取数据来计算
- assign(赋值):将计算好的值从新赋值到工作内存中
- store(存储):将工作内存的数据写入到主内存中
- write(写入):将store过去的变量赋值给主内存中的变量
- lock(锁定):将主内存变量加锁,标识为线程独占状态
- unlock(解锁):将主内存变量解锁,解锁后其他线程可以锁定该变量
这里结合上面的程序外加下面的图来分析

上面的是基本框架,下面的是结合代码执行的流程图,一目了然,更加验证了我们的程序没加volatile的程序逻辑

那么我们结合加了volatile关键字的代码再来分析一下,(提前透露一下volatile就是通过这个总线实现内存可见性的)我们加了volatile修饰的代码后,难道我们的线程2修改了initFlag的之后直接向线程1传输最新修改后的initFlag的值么,嘿嘿这里不要****的想太多,线程之间怎么可能直接传递数据的。
下面我们来详细看看volatile底层到底是怎么实现的往下看!!!
3.CPU缓存一致性协议
早期实现-总线加锁(性能太低)
CPU从主内存读取数据到高速缓存,会在总线对这个数据加锁,这样其他线程CPU没法读取这个或者写入这个数据,直到其当前线程CPU使用完数据释放锁之后,其他线程CPU才能读取/写入该数据数据(这种机制现在已经不再使用了)
结合原来的代码,和上面的基本框架图,在线程1读取主内存区的initFlag时,会对initFlag的数据进行加锁的操作(lock),那么哪个线程对initFlag数据加到锁了,那么就可以正常的操作数据,其他线程也就是我们的线程2就要**等待线程1释放掉锁后(unlock)**才能正常操作这个主内存中的initFlag数据, 那么我们的线程1什么时候释放主内存initFlag变量的锁呢,当然是在线程1执行完毕后才会释放主内存initFlag的锁,其他线程只能等待,那么说白了,这个总线加锁的机制就是把一个原本开线程并行执行的程序变成一个穿行执行的一个程序,性能并不高,鬼哟!!!如果是要串行执行,那****还开线程干嘛,开着玩呀!!!所以这个总线加锁注定就会被摒弃!
现在实现-MESI缓存一致性协议
多个线程CPU从主内存读取同一个数据到各自的高速缓存,当其中某个线程CPU修改了缓存里的数据,该数据立马同步回主内存中去,其他线程CPU会通过总线嗅探机制可以感知到数据变化从而将自己缓存里的数据失效(这也是现在volatile在计算机底层的实现机制,也就是volatile保证内存可见性就是通过MESI缓存一致性协议实现的)
现在开始解释我们的总线-MESI缓存一致性协议(这个偏硬件一点),总线,顾名思义就是线,而且还他妈是真实存在的线,不行打开自己的计算机,会看到内存条和CPU真的是有一排线连接在,这个就是总线,也就是主内存将数据传递到CPU走的就是这个玩意,回到代码层面,看到上面的流程图,当我们的原子性操作将工作线程中的工作内存中initFlag的值同步到主内存的步骤时会经过总线,这个initFlag数据只要经过总线,那么所有的线程CPU都可以同步得到变动的最新值,只要开启MESI缓存一致性协议后,所有的线程都会监听或者是进行一个嗅探这也就是CPU嗅探机制,说白一点就是开启MESI协议后所有的线程都会对总线做监听,这样可以理解为JAVA中的消息队列,当我们往队列里面刷入新值,其他订阅这条消息的服务就会立马收到这个值;当我们的总线被嗅探到,会将线程的工作内存中的值失效掉,那么这个线程就会从新在主内存中从新读取最新的initFlag,这也就有是volatile的简单实现原理了。
volatile缓存可见性实现原理
底层实现主要是通过汇编lock前缀指令,他会锁定这块内存区域的缓存(缓存行锁定),并写会到主内存
这句话有点懵逼,
1.会将当前处理器缓存行数据立即写会到系统内存
2.这个写会内存的操作会引起其他线程CPU里该内存地址数据失效(MESI协议)
这里说明一下volatile底层是C语言实现的,这里C语言也没太多逻辑,还要往下看根深层度的汇编语言
汇编语言这些语言还没投放131239
4.并发编程可见性,原子性,有序向讲解
并发编程的三大特性,可见性、原子性、有序性
volatile保证可见性与有序性,但保证不了原子性,保证原子性需要借助synchronize这样的锁机制
这里直接上新代码
public class Test2 {
public static volatile int num=0;
public static void increase(){
num++;
}
public static void main(String[] args) throws InterruptedException {
Thread[] threads=new Thread[10];
for (int i=0;i<threads.length;i++){
threads[i]=new Thread(new Runnable() {
@Override
public void run() {
for (int i=0;i<1000;i++){
increase();;
}
}
});
threads[i].start();
}
for (Thread t:threads){
t.join();
}
System.out.println(num);
}
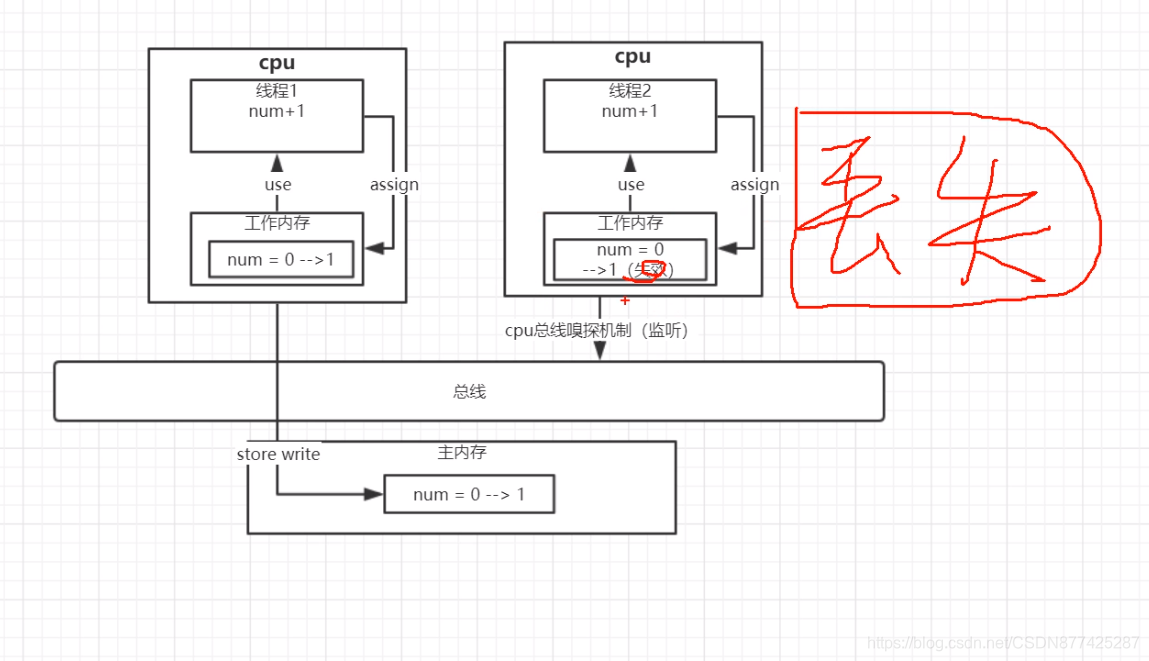
}这里程序输出的结果理论上是会等于10000的,但是不好意思各位,又错了,这里是<=10000,为什么?
结合代码+流程图

由于加了volatile关键字修饰,保证内存可见性,不加内存又不可见,那么加了这个volatile又导致新的问题,结合图+代码分析一下,上面解释volatile开通MESI协议是有个线程工作空间的值失效的操作,那么这里就是这个工作内存中的值失效导致<=10000的情况出现,如图,线程1执行num++时为1,同步到主内存中,其他线程这是也正在进行++操作,那么线程1把值放入主内存的同时会通知其他线程导致其他线程的工作空间的值失效,从而++没加加上,也就到时++操作失效










