开头
提起Spring,大家肯定不陌生,它是每一个Java开发者绕不过去的坎。Spring 框架为基于 java 的企业应用程序提供了一整套解决方案,方便开发人员在框架基础快速进行业务开发。
我最近一直在研究大厂的面试,发现现在的不论大大小小的互联网公司,Spring都是一个绕不开的话题,而且仅仅是 Spring 的面试,从最开始的官网入门到现在源码的深度分析。主要就是四个系列:

二、解析
? 1. 硬件层的并发优化基础知识
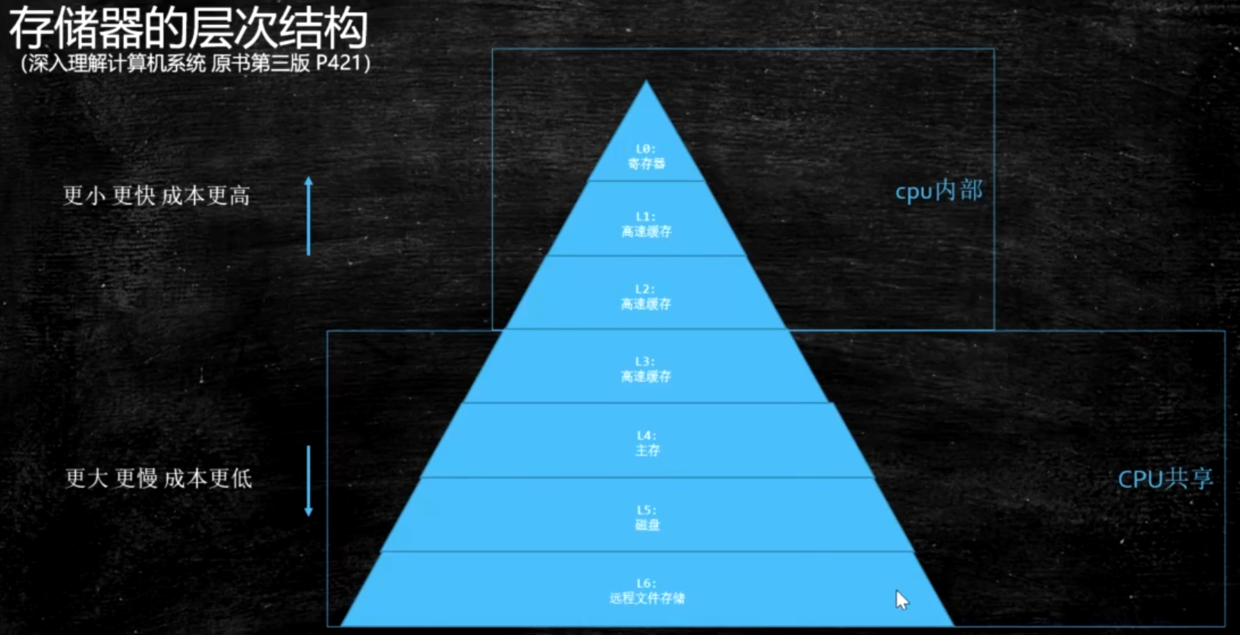
? ?存储器的层次结构图如下:
???
? ?各级缓存耗时对比:
???
? ?采用分层缓存的层次结构会带来数据不一致问题,如下图:
???
? ?那么如何保证数据的一致性,现代CPU处理办法有两种:
? ?(1) 锁系统总线;
? (2) 利用缓存一致性协议MESI(Intel处理器用的比较多,还有很多其他的缓存一致性协议),大致结构如下图:
?
?2. CPU的乱序执行
??CPU中有个乱序执行的概念,概念图如下:
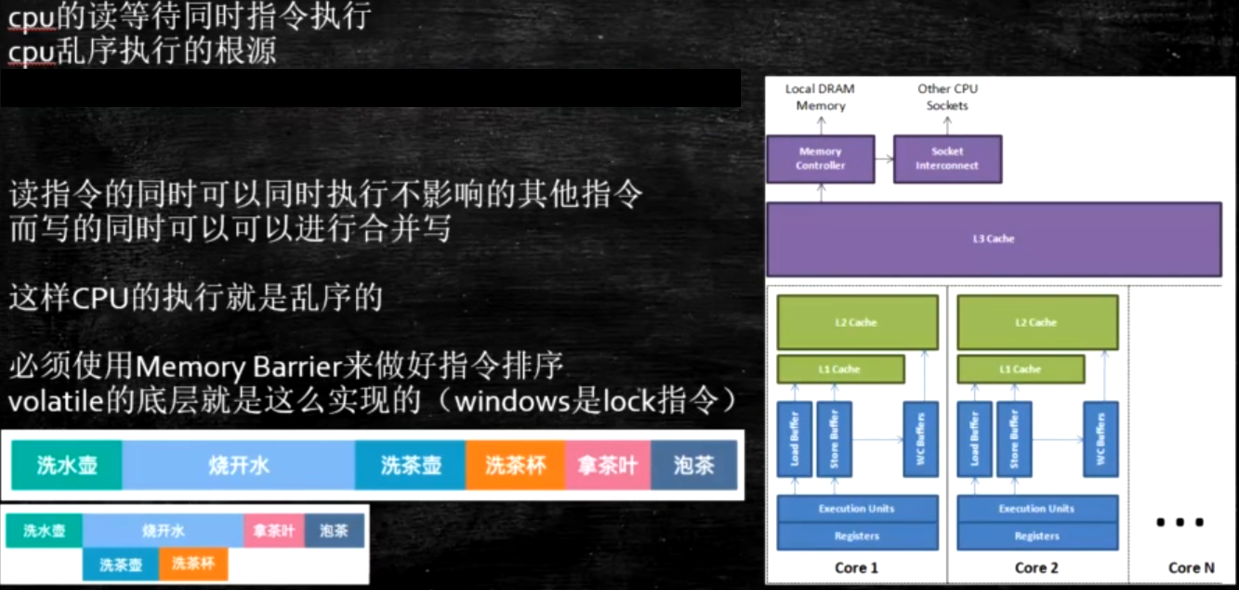
CPU在执行指令的时候,往往不是顺序执行,但是会遵守as-if-serial原则,也就是最终一致性原则。CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据),去同时执行另一条指令,前提是这两条指令没有依赖关系。虽然指令执行顺序发生改变,但是不会影响单线程执行结果。多线程情况下为了不让CUP进行指令重排序,则需要用到Volatile关键字,因为Volatile的重要作用之一就是防止指令重排序。
?CPU还会存在合并写的现象。当第一条指令往上级缓存写入数据时,由于上级缓存访问速度比较慢,可能第二条指令又对上一条指令的结果进行了修改,那么CPU将这两条指令合并的最终结果一次性的写入到缓存中,这就成为合并写。
?3. 如何保证不乱序执行
(1) 内存屏障:java采用的是内存屏障,内存屏障其实就是一个CPU指令,在硬件层面上来说可以扥为两种:Load Barrier 和 Store Barrier即读屏障和写屏障。主要有两个作用:
???a. 阻止屏障两侧的指令重排序;
???b. 强制把写缓冲区/高速缓存中的脏数据等写回主内存,让缓存中相应的数据失效。
《一线大厂Java面试真题解析+Java核心总结学习笔记+最新全套讲解视频+实战项目源码》开源
Java开发优秀开源项目:
-
ali1024.coding.net/public/P7/Java/git
- github.com/spring-projects
总结:绘上一张Kakfa架构思维大纲脑图(xmind)
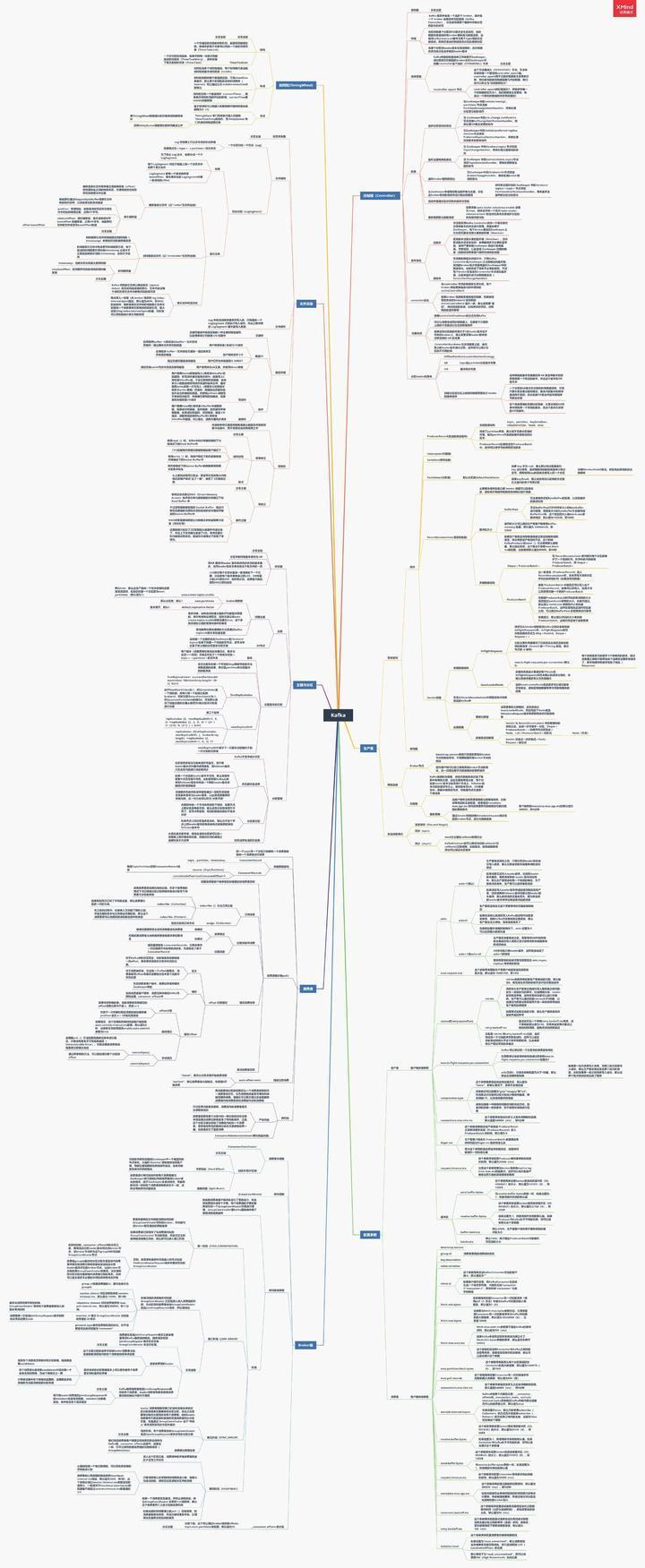
其实关于Kafka,能问的问题实在是太多了,扒了几天,最终筛选出44问:基础篇17问、进阶篇15问、高级篇12问,个个直戳痛点,不知道如果你不着急看答案,又能答出几个呢?
若是对Kafka的知识还回忆不起来,不妨先看我手绘的知识总结脑图(xmind不能上传,文章里用的是图片版)进行整体架构的梳理
梳理了知识,刷完了面试,如若你还想进一步的深入学习解读kafka以及源码,那么接下来的这份《手写“kafka”》将会是个不错的选择。
-
Kafka入门
-
为什么选择Kafka
-
Kafka的安装、管理和配置
-
Kafka的集群
-
第一个Kafka程序
-
Kafka的生产者
-
Kafka的消费者
-
深入理解Kafka
-
可靠的数据传递
-
Spring和Kafka的整合
-
SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
- 数据管道和流式处理(了解即可)












