Spring Data JPA是Spring Data框架的一小部分,它能够让开发者能够更加简单的对数据库进行增删改查。
由于Spring Data JPA可以自动生成SQL代码所以一般情况下,简单的增删查改就可以交给Spring Data JPA来完成,而复杂的动态SQL等用MyBatis来完成。
Spring Data JPA的入门非常简单,接下来请看正文(我使用的是MySQL数据库):
快速入门Spring Data JPA
首先我们先创建一个数据库和表,创建数据库和表的SQL代码如下:
-- 如果存在text数据库就删除该数据库
drop database if exists text;
-- 创建名为text的数据库
create database text charset utf8;
use text;
-- 用户表
create table user_info(
id INT(11) primary key AUTO_INCREMENT,
user_name VARCHAR(20) NOT NULL,
gender INT(1) NOT NULL COMMENT '0.男;1.女',
create_time DATETIME
);创建一个空的Spring项目,我使用的是Spring Boot创建的项目。pom文件中引入的依赖如下:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--lombook:用来自动生成get,set,toString和构造方法等-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--MySQL驱动-->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<!--Spring Data JPA依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
</dependencies>因为Spring Boot默认支持的数据库是H2,所以如果想要使用其他的数据库就必须配置application.properties文件,所以在依赖引入之后还需要修改配置文件,配置文件中除了设置数据库的配置之外还需要设置JPA的配置,但是这个配置也非常简单,只有一行,代码如下:
spring.jpa.hibernate.ddl-auto=update
#设置显示SQL代码
spring.jpa.show-sql=truespring.jpa.hibernate.ddl-auto的取值值有4种:
- none: MySQL默认的配置。不能修改数据库结构;
- update: Hibernate能够根据给定实体类结构来修改数据库;
- create: 每次都创建数据库,但是在关闭后并不进行删除;
- create-drop: 创建数据库,并且当SessionFactory关闭时删除它。
创建JAVA实体类:
package com.example.spring.jpa;
import lombok.Data;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.jpa.domain.support.AuditingEntityListener;
import javax.persistence.*;
import java.util.Date;
@Data
@Entity
@Table(name = "user_info")
public class UserInfo {
@Id
@Column(name="id")
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name="user_name")
private String userName;
@Column(name="gender")
private Integer gender;
@Column(name="create_time")
private Date createTime;
}
@Data: 该注解是Lombook的注解,添加这个注解后程序会在编译阶段自动生成get,set,toString,无参构造方法等基础方法。
@Entity: 该注解表示这个类是一个JPA实体。
@Table: 该注解表示这个实体和数据库中表的对应关系。如果没有该注解就默认对应的数据库中表的名称为类名即:UserInfo。name属性的值为数据库中对应的表名。
@Id: 表示该属性为主键。
@Column: 该注解表示这个属性和数据库中字段的对应关系。name属性的值为数据库中对应的字段名。如果没有该注解则默认属性名就是字段名。
@GeneratedValue: 提供主键值的生成策略规范。有四种取值默认为AUTO即自动生成ID。
编写持久层的代码,只需要加上@Repository注解并继承CrudRepository接口,接口传的类型为<实体类型,主键类型>:
package com.example.spring.jpa;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends CrudRepository<UserInfo, Integer> {
}编写业务逻辑层代码:
package com.example.spring.jpa;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class JpaService {
@Resource
private UserRepository userRepository;
//添加数据
public Object insertUserInfo(UserInfo userInfo) {
return userRepository.save(userInfo);
}
//根据id删除数据
public void deleteUserInfo(Integer id) {
userRepository.deleteById(id);
}
//修改数据
public Object update(UserInfo userInfo) {
return userRepository.save(userInfo);
}
//查找数据
public Object selectUserInfo() {
return userRepository.findAll();
}
}
这些方法都是来自CrudRepository接口,它里面定义了常用CRUD接口。
如果你仔细观察就会发现插入数据和修改数据使用的是同一个接口,它会根据主键值是否存在于数据库中来判断是修改还是插入。
编写控制层接口:
package com.example.spring.jpa;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
@RequestMapping("/jpa")
public class Controller {
@Resource
private JpaService jpaService;
@RequestMapping("/delete")
public void delete(Integer id) {
jpaService.deleteUserInfo(id);
}
@RequestMapping("/select")
public Object select() {
return jpaService.selectUserInfo();
}
@RequestMapping("/insert")
public Object insert(UserInfo userInfo) {
return jpaService.insertUserInfo(userInfo);
}
@RequestMapping("/update")
public Object update(UserInfo userInfo) {
return jpaService.update(userInfo);
}
}
到此为止你已经入门了
JAP是如何区分你是想要插入数据,还是修改数据?
接下来我们使用Postman进行测试,用结果和它所对应现象来说话

细心的小伙伴可能会发现当程序刚一启动数据库中就自动创建了一个不认识的表:

如果没注意的话你可以将数据库删除重新创建,然后再重新启动一边程序。
那么这个表是干啥的?有啥用呢?往下看
根据控制台打印的SQL语句我们可以知道,程序先查询并设置了hibernate_sequence表中的内容,然后才进行的插入操作,注意此时我们没有给id传值。

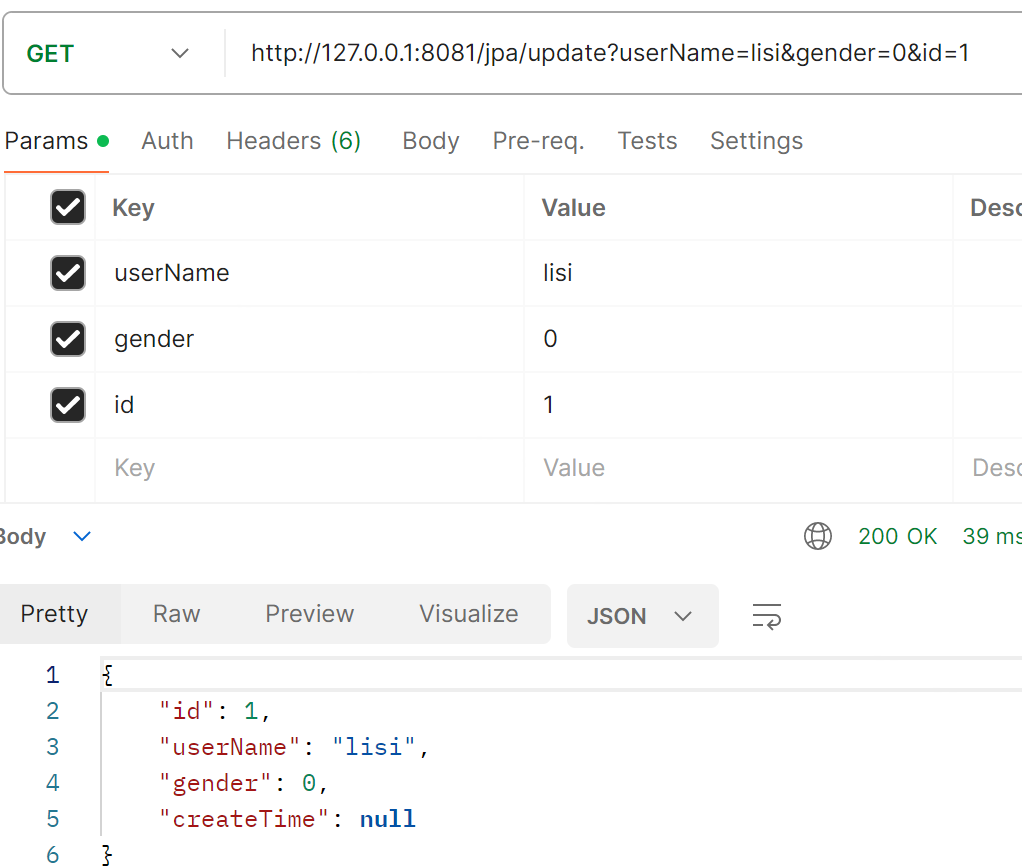
执行完修改操作后我们可以从响应中发现修改成功了,接下来我们再看一下控制台打印的SQL语句,注意此时我们给id传值了:

我们可以发现程序是先根据id来查找到值之后才进行的修改。
接下来我们再插入时给id赋予初值然后再来看结果:
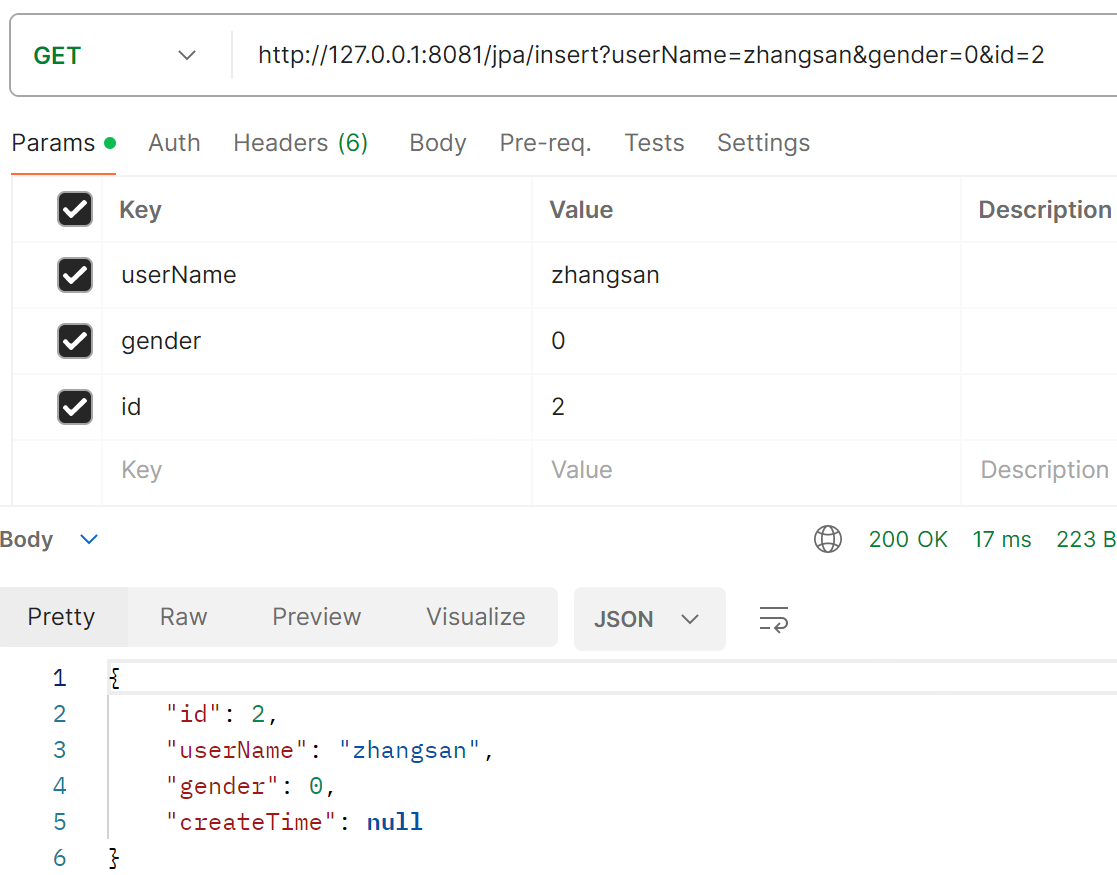
注意看:此时的SQL语句中可以看出来程序是先根据id查找表中的对应书据,发现没找到,然后才查询并设置了hibernate_sequence表中的内容,然后才进行的插入操作。

总结:
程序会先判断主键是否有初值,如果没有就执行插入操作;否则根据该值来查找对应的数据,如果找到就执行修改操作;否则就执行插入操作;
针对项目自定义查询
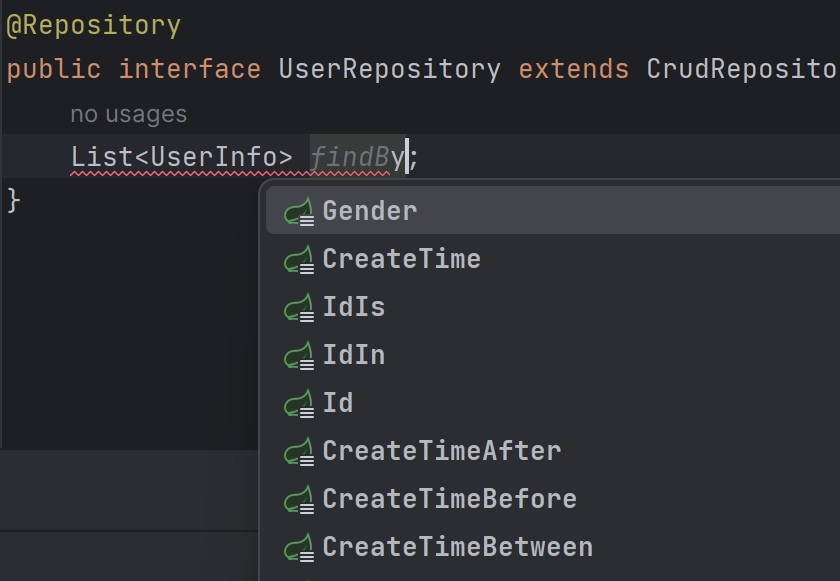
我们上面使用操作数据库的方法都是CrudRepository接口中的方法,那么就算它再全也不可能覆盖所有的接口,所以我们还可以针对自己的项目进行自定义接口,例如我现在想要根据gender来查询用户信息:
在UserRepository接口中添加一个方法:
package com.example.spring.jpa;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
import javax.persistence.criteria.CriteriaBuilder;
import java.util.List;
@Repository
public interface UserRepository extends CrudRepository<UserInfo, Integer> {
List<UserInfo> findByGender(Integer gender);
}
为了方便起见,我们直接在控制层调用:
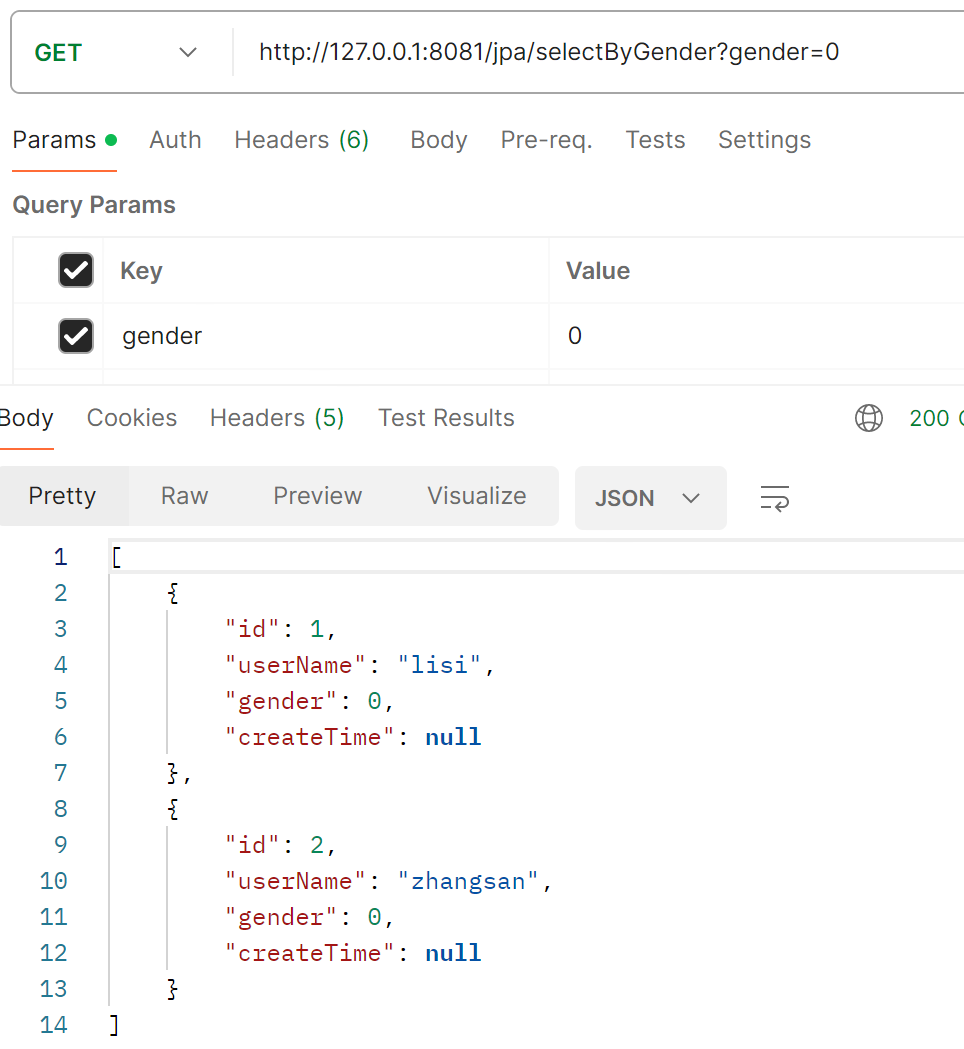
@RequestMapping("/selectByGender")
public Object select(Integer gender) {
return userRepository.findByGender(gender);
}
注意:虽然他给了我们自定义接口的能力,但是接口的命名必须符合要求。在IDEA中编译器就会进行提示: