这个实验的逻辑是这样的
需要使用gdb debug 进入到phase_x的各个函数,但是单步调试step是进不去的(也不难理解,如果gdb可以直接进入那这个实验还有什么难点)
但是反汇编得到的结果是全部的内容,通过阅读反汇编代码,找到一些关键节点,通过gdb对二进制进行dubug添加breakpoint从而查看一些内容找到结果
```shell
objdump -d bomb > bomb.txt
```
打开反汇编代码,往下看发现了居然是按函数都分好了,真是万事开头难,开始真的不知道要怎么开始,所以有些事大胆往前走,前面或许不像你想的那么困难

`read_line`内容放在%rax中,传到%rdi,对应`input = read_line()`

查询[汇编中 $ 和 % 符号的作用](http://blog.chinaunix.net/uid-28458801-id-3555479.html)发现了以下内容
> DOS/Windows 下的汇编语言,这些汇编代码都是 Intel 风格的。但在 Unix 和 Linux 系统中,更多采用的还是 AT&T 格式,两者在语法格式上有着很大的不同
1. 在 AT&T 汇编格式中,寄存器名要加上 '%' 作为前缀 `pushl %eax`
2. 在 AT&T 汇编格式中,用 \$前缀表示一个立即操作数 `pushl $1`
3. **目标操作数在源操作数的右边** `movl $1,%eax`
4. 操作数的字长由操作符的最后一个字母决定 b,w,l
这里需要清楚test指令的用途
TEST 指令在两个操作数的对应位之间进行 AND 操作,并根据运算结果设置符号标志位、零标志位和奇偶标志位
**ZF**:零标志位。相关指令执行后结果为0那么ZF=1,结果不为0则ZF=0
所以如果%eax为0,那么zf就为1,反之zf为0
而je是在zf为1时跳转,即在%eax为0时进行跳转
> je在zf为1时进行跳转,相等为什么等价于zf为1呢?、
>
> cmp a b,当a和b相等时zf也为1,为什么两个数相等等价于0标志位为1呢?
>
> 答:cmp的比较方法是通过隐含的减法实现的,减法会使得一些标志位发生改变,条件跳转指令就是根据这些标志位来判断比较的结果
上面这些疑问是对于汇编语言本身的疑问,现在我们就单纯接受这些结论,考虑在这里的逻辑
这块的逻辑是调用strings_not_equal,如果strings_not_equal返回的是0就跳转到400ef7即炸弹拆除成功,否则跳转到40143a,即炸弹拆除失败

所以答案实际上是处在strings_not_equal这个函数中的,所以下面去找这个函数
这个函数的汇编代码还是比较长的,乍一看不知道看什么就迷茫了
这时候一个突破点是函数的返回值是通过eax寄存器传递的
所以到strings_not_equal可以找一下eax

当%eax为0时代表拆除成功,所以重点在上面那两个跳转
## `strings_not_equal`流程分析
1. 调用string_length函数计算字符串长度,函数将长度放在%eax中,返回将将结果存储在%r12d中

2. 再次调用string_length函数计算另一字符串长度,函数仍将结果放在%eax中,但是由于只有两个字符串,所以不需要将%eax的结果另外存储了

3. 相当于提前定义了答案变量并设置默认值为1`res = 1`,返回1会引发爆炸

4. 比较两个字符串是否相等,首先计算了两个字符串的长度,然后比较两个字符串长度,如果两个字符串长度不相等那么一定不相同了,跳转到0x40139b处

而0x40139b处事将%edx放到%eax中,这个%eax就是存储函数的返回值


在标志位zf为0时会进行跳转,zf是是否为0的标志位,zf为0代表test结果不为0,因此%al不为0
## phase_1实际应当的解题流程
1. 按照bomb.c文件的代码,找到phase_1上方的read_line,下面mov语句
就是将读入的字符串放入到rdi寄存器中

2. 之后去查找phase_1函数,对于红色框通过搜索test和je指令,可以发现这部分的结果事如果%eax为0则拆除成功,如果为1则拆除失败,而%eax的的值事通过`stirngs_not_equal()`得到的(这里了解到的是函数的返回值一般都放置在eax中);对于绿色框,实际是在定义一个答案字符串,我在看到这里时并没有想到这一点,这个答案字符串可能是放在这里的,也可能是放在strings_not_equal函数中的,具体情况还应当到函数中看过之后才可以确定,但是对这里必须有印象
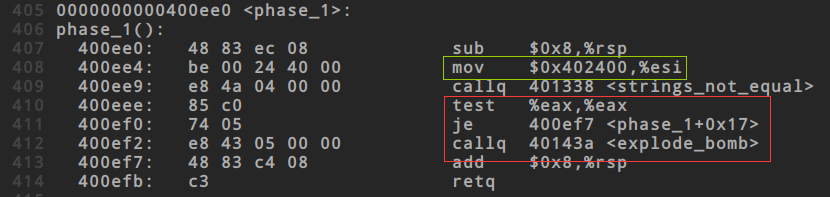
3. 之后来到`strings_not_equal`函数内部,这个函数略有复杂,
- 大红色框
将输入的字符串和答案字符串换了个位置,rdi存储的输入字符串,rsi那就是答案字符串了,所以也就印证了phase_1中的esi存储的就是答案字符串的位置,但是注意仅仅看到这里并不能确定答案字符串就处在esi的位置,起始位置要看从哪一位开始比较的,毕竟rsi只是个地址,比较的起始位置到此还不能确定
- 绿色框
这里是在比较字符串长度,这个不难理解,我们在判断两个字符串是否相等时也是首先判断字符串长度是否相等
- 橙色框
(%rbx)是间接寻址,rbx寄存器存储的是字符串在内存中的地址,现在将字符串取出来放到eax中,然后检查eax是否为0,ascii为0的字符是空字符(null),如果是空字符按它的结果直接返回0,但实际输入过程我们不可能输入空字符,所以这里对于解题没有什么作用,跳过即可
橙色框上方一句话将输入字符串rbx放入到eax中,橙色框的判断逻辑是如果输入字符串为0,那么test的结果是zf标志位变为1,从而满足je的跳转条件,跳转到将edx的值设置为0,之后跳转到40139b,将edx的值赋值给eax,然后程序返回
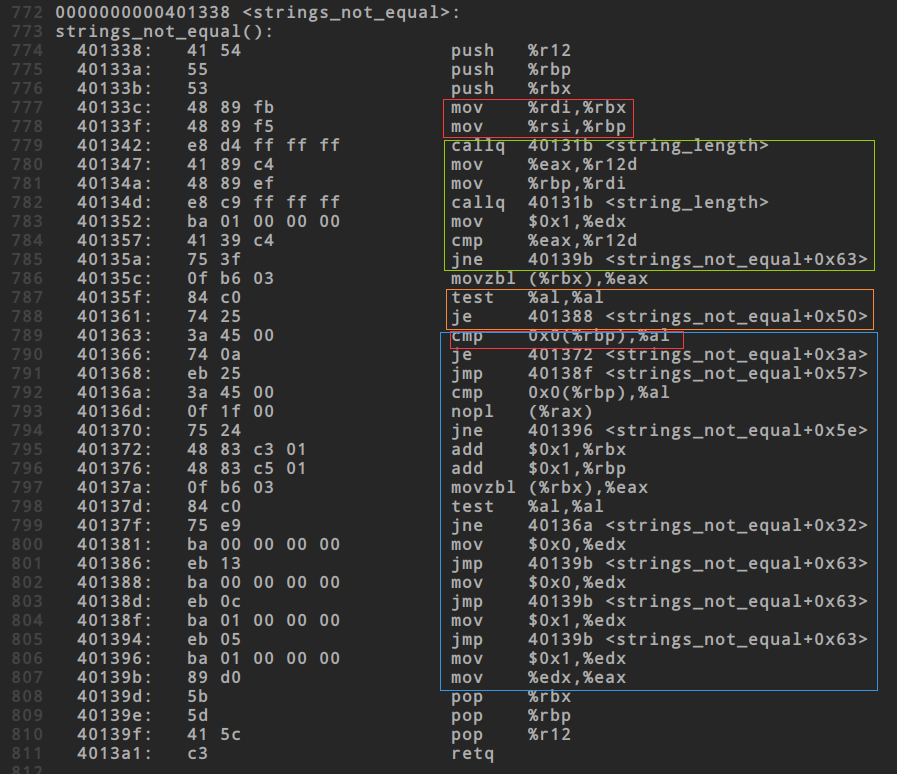
- 蓝色框
这部分按我的理解就是这个字符检查是否相等
解题的关键在于确定是从哪个位置开始遍历的,找到开始遍历的位置也就找到了答案字符串,注意蓝色框中的小红色框,上方的`movzbl (%rbx) %eax`就将输入字符串放到了eax中,而al是eax中的最低的那8位,与输入字符串进行比较的是`0X0(%rbp)`,从这里就可以确定了答案字符串就是rbp中存储的那个内存地址,而具体的值还要回到phase_1那里去查看,发现是0x402400
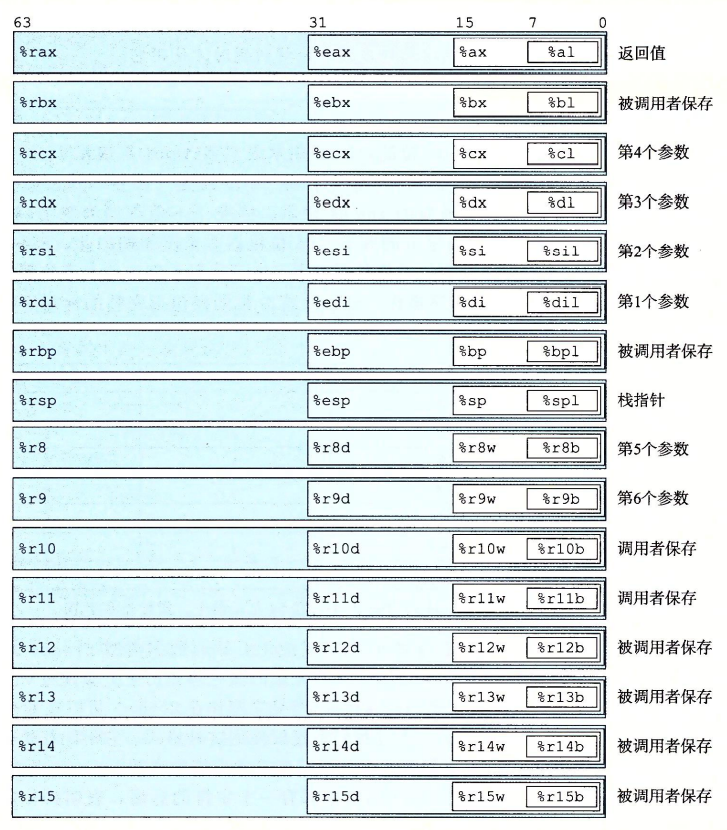
下图是寻址方式和寄存器图示,是理解汇编代码的核心所在
## phase_2流程
1. 还是先找read_line找输入字符串

input保存在%rdi中
2. 然后找phase_2函数
整体的跳转过程如下图所示,分别进行分析
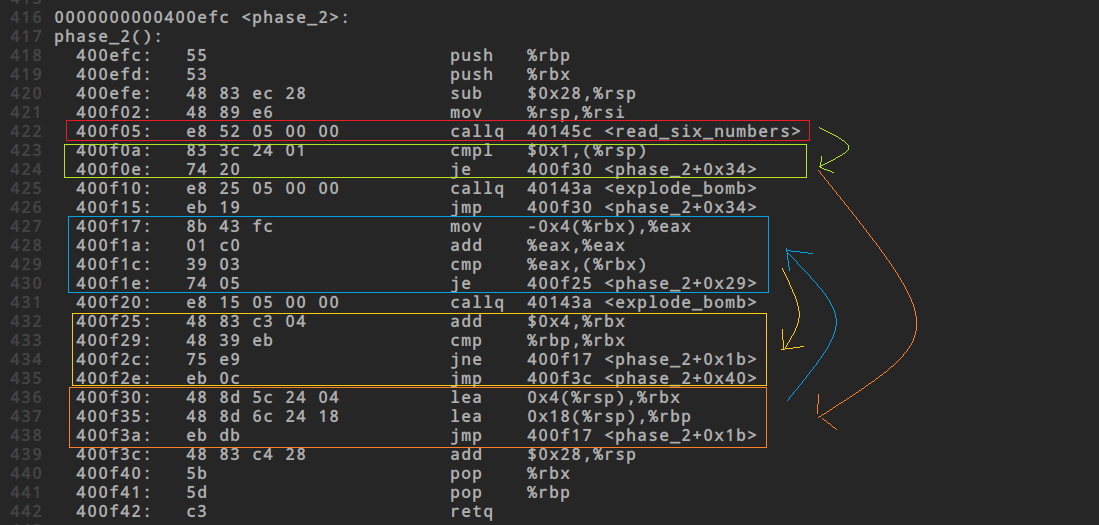
3. 首先是这里的函数调用`read_six_numbers`(红色框)于是进入`read_six_numbers`,发现这里有两个重点通过gdb查看0x4025c3这个地址,内容是"%d %d %d %d %d %d",结合`sscanf`,得知`read_six_numbers`是从input中读取到6个数据,这里暂时没有分析这6个数据各自存储到了哪个寄存器,先尝试着向下分析
4. 回到phase_2函数(绿色框)
这里的比较非常重要,如果(%rsp)不等于1,那么就直接爆炸了,所以比较的最初条件是(%rsp)为1
5. 橙色框
这部分的关键是`lea`指令,这个东西查询结果很混乱,怎么说的都有,根据实际表现,推测它的作用是`lea a b`等价于`&a -> b`,即将a的地址放入b中,所以`lea 0x4(%rsp), %rbx`的结果是%rbx = M[R[%rsp] + 0x4],即寄存器rsp中存储的是一个基地址,R[%rsp]的意思是将寄存器存储的值取出来,即获得这个基地址,然后加上偏移量0x4,得到一个新地址,M[新地址]的意识是去内存中的这个地址取出这个数值,最后将这个数值的地址让rbx寄存器负责存储,所以rbx存储的就是那个新地址,即R[%rsp] + 0x4,同理让rbp存储R[%rsp]+0x18
6. 蓝色框
注意此时的前提是%rbx = &(R[%rsp] + 0x4), 即R[%rbx] = R[%rsp] + 0x4,通俗地说rbx这个寄存器实际存储的是一个地址,内存中这个地址存储的是我们要的数值
`mov -0x4(%rbx), %eax`的效果是%eax = M[R[%rbx] - 0x4] = M[R[%rsp] + 0x4 - 0x4] = M[R[%rsp]] = (%rsp),即%eax = 1,而此时(%rbx) = M[R[%rbx]] = M[R[%rsp + 0x4]],实际表现是此时(%rbx)等于我们输入的第二个数据,相当于两个数据在内存中地址相差了4,通过gdb可以验证%eax和(%rbx)两个值
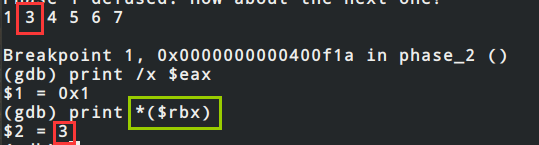
综上,蓝色框实际做的是把1翻倍为2,然后与我们输入的第2个数据进行比较
7. 黄色框
这部分会把rbx的值加上0x4,然后与rbp进行比较,直到两者相等时跳转到400f3c,可以看出如果发生该跳转,说明函数结束了,否则会再次跳转到蓝色框
可以发现,之后的过程一直是蓝色框和黄色框的跳转,黄色框像是一个边界判断,而蓝色框则进行的是数值的比较
蓝色框和黄色框中涉及到的寄存器有rbx和eax,rbx一直在+0x4,eax则负责数值的存储并且翻倍,gdb在0x400f29添加断点进行debug可以得到以下结果
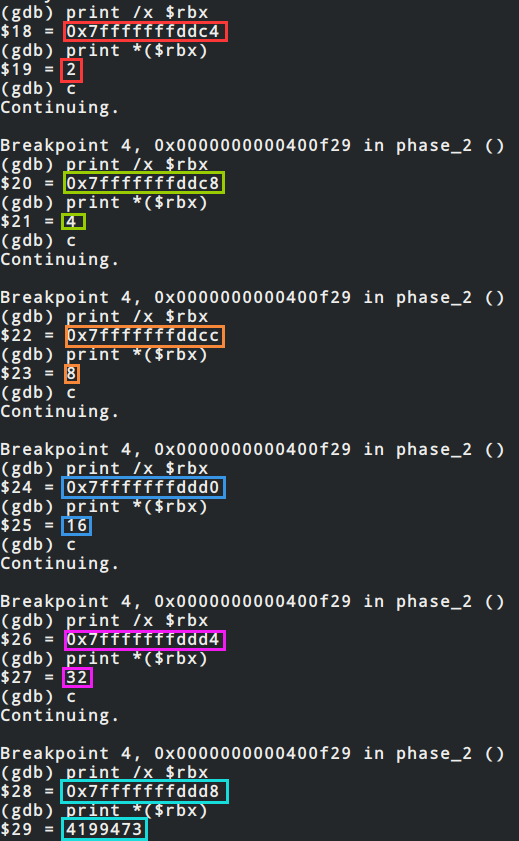
所以内存中的存储形式是

总结:phase_2解题的关键在于看懂跳转流程,其中对于lea指令的理解非常重要
phase_1的答案是内存中存储的某个字符串,phase_2还按照这种思想去找是找不到的,因为它的答案是通过运算得出的
## phase_3流程
1. 读入数据

2. 查看phase_3函数
跳转过程
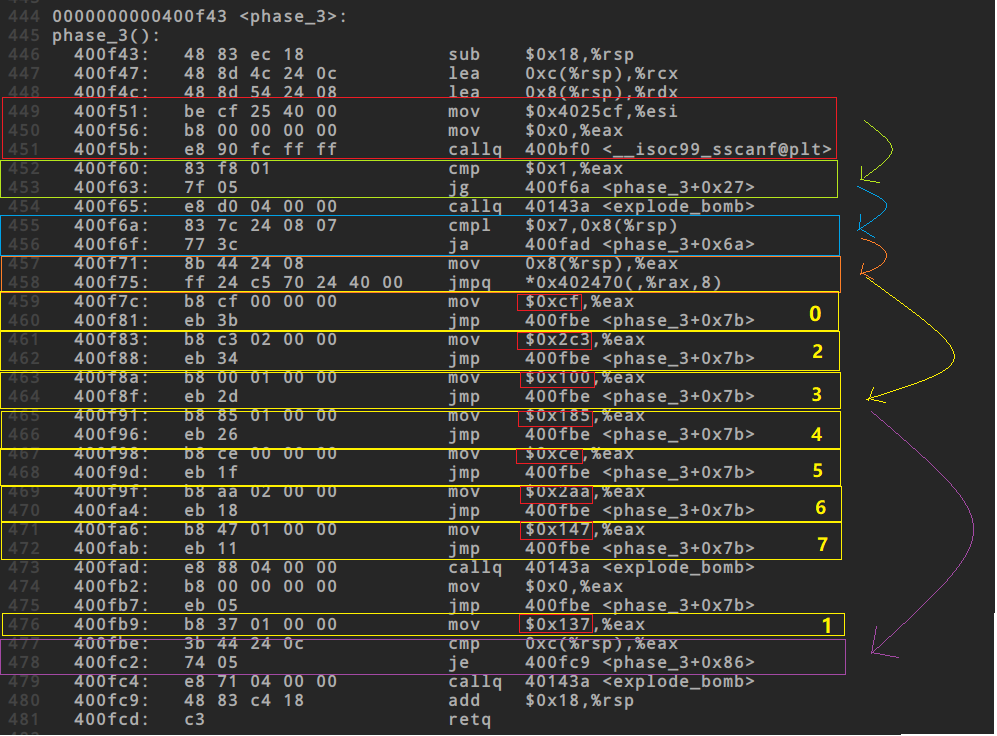
3. 红色框
首先根据sscanf和0x4025cf,可以得知输入数据应当为2个数通过gdb可以确定的是0x8(%rsp)就是我们输入数据的第一个值,0xc(%rsp)是输入数据的第二个值
4. 蓝色框
根据蓝色框可以得知以下内容
1. cmp是比较后面的数据与前面数据的关系
1. 第一个输入的数据必须小于等于7,否则直接爆炸
5. 橙色框
这里跳转的地址是比例变址寻址,需要手动计算。这里我犯了一个错误,在计算后输出结果时,应当选择16进制输出,结果我是按照10进制输出的应当选择,`print /x` 或 `x/x`
> 疑问
`jmpq *0x402470(,%rax,8)`
实际情况是`M[0x402470 + r[rax] * 8]`的结果是一个地址,即内存中地址为`0x402470 + r[rax] * 8`的位置存放了一个地址,到内存中这个地址取出来的数据是一个地址,实际跳转到的就是取出来这个数据的地址,但是前面还有个*号,这个\*号起到了什么作用?
这里跳转的结果是由我们输入的第一个数据决定的,第一个数据只需小于等于7即可,下表列出当第一个输入数据不同时所对应的跳转指令
| 第一个参数 | 0x402470+r[rax]*8 | 跳转指令 |
| ---------- | ----------------- | ----------------- |
| 0 | `0x402470` | `jmpq 0x00400f7c` |
| 1 | `0x402478` | `jmpq 0x00400fb9` |
| 2 | `0x402480` | `jmpq 0x00400f83` |
| 3 | `0x402488` | `jmpq 0x00400f8a` |
| 4 | `0x402490` | `jmpq 0x00400f91` |
| 5 | `0x402498` | `jmpq 0x00400f98` |
| 6 | `0x4024a0` | `jmpq 0x00400f9f` |
| 7 | 0x4024a8 | `jmpq 0x00400fa6` |
6. 黄色框
黄色框内的红色框即为第二个答案,放入到eax寄存器中
| 第一个参数 | 第二个参数 |
| ---------- | ---------- |
| 0 | 207(0xcf) |
| 1 | 311(0x137) |
| 2 | 707(0x2c3) |
| 3 | 100(0x256) |
| 4 | 389(0x185) |
| 5 | 206(0xce) |
| 6 | 682(0x2aa) |
| 7 | 327(0x147) |
7. 紫色框
将第二个输入数据同eax中存放的答案进行比较
## phase_4流程
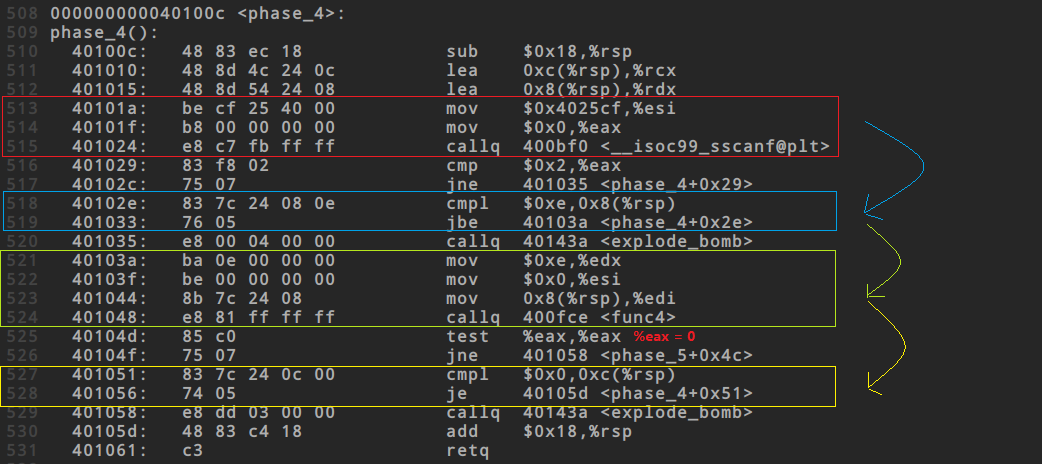
1. 红色框
读入数据包含2个数
2. 蓝色框
第一个数据必须$<= 14$
3. 绿色框
初始值
> %edx = %rdx = 0xe
> %esi = %rsi = 0x0
> %edi = %rdi = 输入的第一个数据
开始调用函数`func4()`,该函数返回值必须为0,即%eax必须为0
4. 黄色框
第2个输入数据必须为0
把整体流程走了一遍,两个输入已经确定了后一个,现在还需要确定前一个,解决问题的关键在于绿色框中的func4函数
5. 进入func4函数
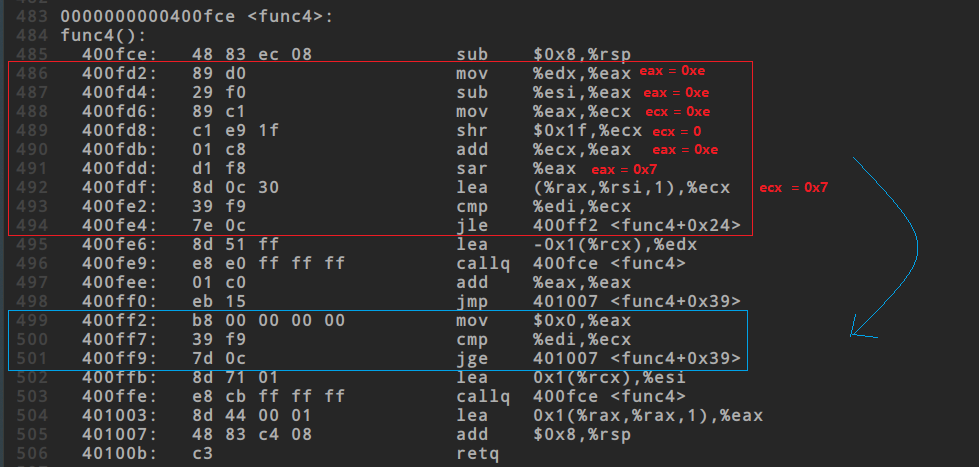
6. 红色框
这里的难点主要是一些运算,当然直接使用gdb是个偷懒的方法,可以直接获得ecx的值为0x7
之后会进行一个比较,edi中存储的是第一个输入的数据,当$edi <= 7$时会跳转到蓝色框
这里我们并不知道跳转或不跳转会发生什么,不妨尝试一下令$edi <= 7$并发生跳转
7. 蓝色框
第一步把eax置为0,这正是phase_4中的合法值
之后比较edi和ecx,即0x7
当$edi >= 7$时发生跳转,结束该函数
此时的返回值已经是合法的了,如果直接返回即可解决问题
所以只需要让两次跳转全部发生即可,两次的条件分别为$edi <= 7$ 和 $edi >= 7$,全部满足的条件是$edi == 7$
所以可以确定最终答案为 7 0
## phase_5流程
1. 读入

读入字符串放入到%rdi中
2. phase_5函数
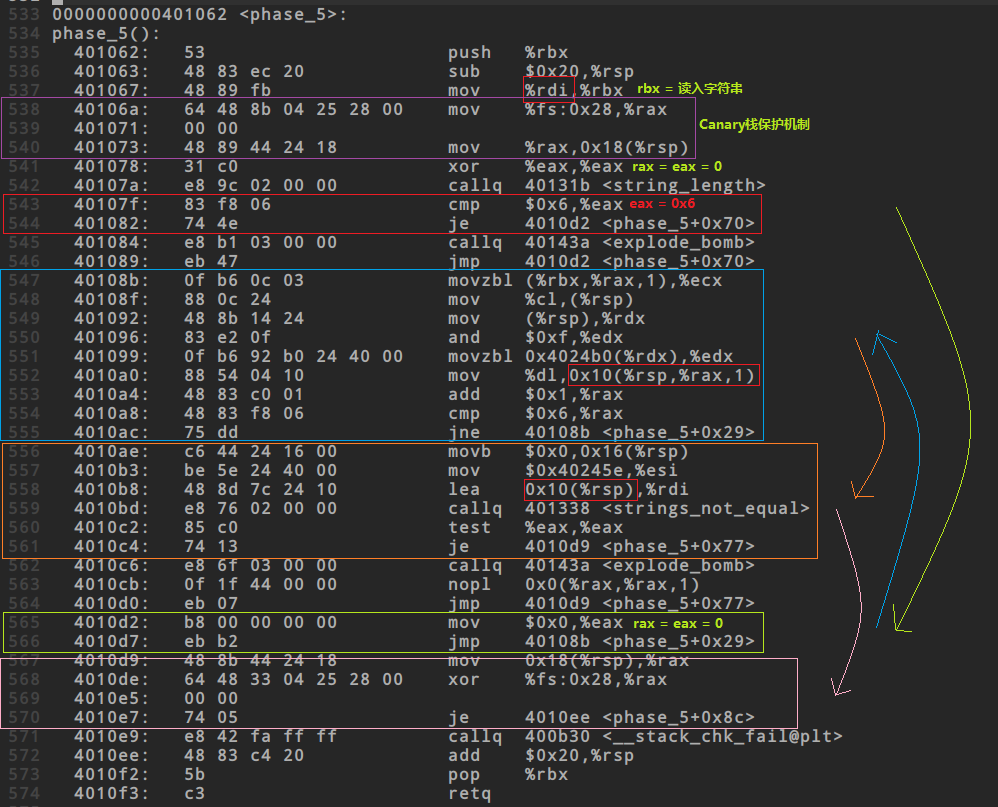
3. 红色框
上方恰好有一个函数调用`string_length`,eax恰好是函数返回值
这里eax必须等于6,否则直接爆炸,因此可以确定答案是一个长度为6的字符串
4. 绿色框
这里只是将eax赋值为0,然后跳转到蓝色框
5. 蓝色框
rax每次加1,直到等于6时跳出蓝色框,否则一直在重复执行
初始条件:
> rbx是输入的字符串
>
> rax = 0
因为6轮的代码是一样的,所以每一轮的处理逻辑都是相同的,我们只需要搞清楚第一轮是如何处理的,rax = 0时
M[R[rbx]] -> rcx
rcx -> M[r[rsp]]
M[r[rsp]] -> rdx
rdx & 0xf -> rdx
M[0x4024b0 + R[rdx]] -> rdx
rdx -> M[0x10 + R[rsp]]
精简一下的结果是:
M[R[rbx]] -> rdx
rdx & 0xf -> rdx
M[0x4024b0 + R[rdx]] -> 内存中某个位置
可以发现,这一段循环就是在把一些数据填充到内存中一些位置,如果我们看过橙色框中的内容,可以发现上述代码最终放入的内存地址在下方有出现过,
当rax等于0时,这一段循环最终将一个数据放入到了M[0x10 + R[rsp]]中,而查看橙色框可以发现,这个位置刚好为%rdi的起始数据,而我们知道%rdi正是`strings_not_equal`其中一个比较项
`strings_not_equal`中另一个比较项esi在橙色框中是给定的,现在的核心是搞清楚上述数据填充的规则,使其填入的恰好为esi的内容`flyers`相同即可
通过上述大体的分析,可以了解到这个循环大体上在做什么,以及我们的目标是什么,但是要搞清楚具体的操作逻辑,还是要仔细进行分析
首先将读入字符串的第一个字符放入ecx中
一个字符仅占1个字节,即8bit,所以ecx中仅低8bit是有效数据,所以这里使用了cl
之后把cl存储的这个字符内容放到rdx中
之后用`00001111`与edx进行按位与放入到edx中
之后以0x4024b0作为基地址,以rdx的值作为偏移量,从内存中取出数据放入到edx中
最后将edx放入到目标位置
根据上述分析,现在可以做的是查看一下内存中0x4024b0这个地址存储的内容是什么
> (gdb) x/s 0x4024b0
> 0x4024b0 <array.3449>: "maduiersnfotvbylSo you think you can stop the bomb with ctrl-c, do you?"
前面的字符串中包含了我们所需的所有字符,就像一个数组,我们要构造下标将需要的字符取出来
我们需要的字符串是`flyers`,即所需的下标依次为9,15,14,5,6,7
而这些数字是通过字符的ascii与00001111进行按位与得到的,所以我们需要的ascii可以是ionefg,以下数据从左到右依次是它们的ascii码与00001111按位与的结果,字符,字符的ascii码
9 i 105
15 o 111
14 n 110
5 e 101
6 f 102
7 g 103
6. 橙色框
这里的主要内容就是`strings_not_equal`,根据之前的实验,这个函数就是判断rdi和esi内容是否相同
总结:
从整体上来看,这道题解题的关键就在于搞懂蓝色框的内容
从细节上来看,难点在于,多个寄存器和寻址方式的使用,让人眼花缭乱同时由于对于各种寻址方式并不是什么确定,本身存在着自我怀疑,所以深入阅读有些困难,还是要有自信,分析之后可以发现有些内容你想的就是正确的,要坚定信心
## phase_6流程
`read_six_numbers`把输入的数据读入到寄存器中
1. 1号框
首先把rsp存储数据减少0x50
之后把rsp的数据放入到r13中,可以验证得到它们存储的数据指向的内存区域存储的是第一个输入的数据
2. 2号框
红色框中得到结论是rsp中存储的第一个输入数据的地址,所以eax的结果是第一个输入的数据,减去0x1后需要保证<=0x5,因此**第一个输入的数据需要保证<=0x6**
3. 3号框
上次出现r12的位置是在绿色框的588行,赋值为0x0
加上0x1后判断是否等于0x6,显然不等于,于是向下继续
根据运算可以相继计算处ebx = 1,rax = 1
`mov (%rsp, %rax, 4), %eax`在rax = 1时是将第2个输入的数据放入到eax
之后比较eax和rbp的值,上次出现rbp的位置是在绿色框中的`mov %r13, %rbp`,即输入数据的第1个数据
所以这里是在比较输入数据的第1个和第2个,这里必须保证两者不能相等
4. 4号框
首先对ebx加1,蓝色框中ebx=1,所以这里等于2
然后判断ebx与5的大小关系,在ebx$<=5$时跳转回蓝色框,将rax赋值为ebx
这里不难相出是在做什么,ebx<=5实际代表的就是rax<=5,rax处在取数的代码中,所以这里的循环就是在判断**6个数中的后面5个是否均不同于第1个**
**验证上述逻辑的判断**
初始输入数据为 4 5 6 1 2 3
在40113e处添加断点,每次停下时检查%eax和(%rbp)的值,结果依次是
| 次数 | %eax | (%rbp) |
| ---- | ---- | ------ |
| 1 | 0x5 | 0x4 |
| 2 | 0x6 | 0x4 |
| 3 | 0x1 | 0x4 |
| 4 | 0x2 | 0x4 |
| 5 | 0x3 | 0x4 |
5. 14号框
r13上一次出现的结果是指向输入的第1个数据存储的地址
这里对地址加上4,效果是让其指向了第2个数据
然后跳转到绿色框中,再走一次上面的过程
也就是说还需要保证 **第2个数据<=0x6** 和 **第2个数据后面的数据均与第2个数据不同**
6. 对以上内容进行总结
上述是一个两重循环,对数据合法性进行了判定,应当满足的要求有两点
1. 所有数据$<=0x6$
2. 任意两个数据不相等
因此可以得知,正确答案就是一个从1,2,3,4,5,6这几个数的一种排列
显然后续过程就是对这种排列顺序进行一个约束
7. 5号框
首先rsi存储输入数据的边界
r14上次出现的位置是在绿色框,被赋值为%rsp,即输入数据的第一个值,用rax进行存储
之后定义ecx为0x7
之后令edx为ecx,即0x7
之后用edx减去当前指向的数据,即rax指向的数据
之后将上一步的结果存储到内存中原数据的位置
之后令rax+4,即指向下一个数的位置
在rax没有到达rsi这个边界之前一直重复上述过程
所以,这一部分完成的事情是将各个输入数据修改为0x7减去各个数据
通过在0x40116f处添加断点可以确定这一点
8. 6号框
将rsi(esi)置为0,跳转到粉色框
8. 9号框
查看0x6032d0地址的内容
> (gdb) x /12x 0x6032d0
> 0x6032d0 <node1>: 0x000000010000014c 0x00000000006032e0
> 0x6032e0 <node2>: 0x00000002000000a8 0x00000000006032f0
> 0x6032f0 <node3>: 0x000000030000039c 0x0000000000603300
> 0x603300 <node4>: 0x00000004000002b3 0x0000000000603310
> 0x603310 <node5>: 0x00000005000001dd 0x0000000000603320
> 0x603320 <node6>: 0x00000006000001bb 0x0000000000000000
这是一个链表的结果,前面一个链接着后面一个
10. 7号框
这是一个循环,rdx指向一个链表空间,ecx存放的是输入的第一个数据(被7减之后的数据),eax从1开始
每次循环rdx向后移动一个空间,eax自增1,当eax等于ecx时循环结束
假设ecx=4,则最终rdx指向的就是<node4>
11. 8号框
把rdx放到地址为rsp + rsi * 2 + 0x20的内存空间中
rsi增加4
之后的判断是在判断是否达到输入空间的终点
12. 10和11是第一次的过程,当rsi增加4后,会把10和11的过程再进行一次
不过我们没有考虑9号框的判断语句,这里的判断第一个输入数据是否为1,如果为1,那么跳转到401183,把链表第一个空间的值放入edx,之后把这个值放入指定的内存空间,之后正常循环
观察它的循环结构,为1的时候是没办法处理的,因为上来就跳到第2个位置,所以相当于对1做的特判
7,8,9,10构成了一个循环,从9号框开始循环,8号框最终结束循环,循环结束的出口为0x4011ab。这段的效果就是,假设我们输入的第一个数据为3(被7减过的结果),那么就将链表第3个节点的地址放入到指定内存空间,假设原始输入为4 5 3 1 2 6,那么处理后数据为3 2 4 6 5 1,最终内存结构示意图如下

注意这里是根据我们输入的值,决定将链表中第几个节点的地址放入到指定内存空间,不是把我们输入的值放入指定内存空间
13. 11号框是一个循环
第一次循环的初始条件是(具体数值我们采用上面的例子)
`mov 0x20(%rsp), %rbx`: rbx是指定内存空间的第1个空间,结果是node3初始地址
`lea 0x28(%rsp), %rax`: rax值是指定内存空间的第2个空间的地址
`mov %rbx, %rcx`: rcx存储的值域rbx相同,为node3初始地址
进入第一次循环
1. `mov (%rax), %rdx`: rdx的值是第2个空间的值,即node2的初始地址
2. `mov %rdx, 0x8(%rcx)`: node3->next = node2
3. `add $0x8, %rax`: rax的值为第3个空间的地址
4. `mov %rdx, %rcx`: rcx的值是node2的初始地址
循环的结果是链表变为node3->node2->node4->node6->node5->node1
加上4011d2,就构成一个完整的链表了node3->node2->node4->node6->node5->node1->NULL
14. 12号框进行了一次比较
rbx上次出现的位置在10号框下方,它的值相当于链表首地址
eax是链表第2个元素的值,(%rbx)是第1个元素的值,必须保证第1个元素大于第2个元素
13号框把rbx的值修改为链表第2个节点的地址,之后继续进行12号框,所以12号框和13号框构成一个循环,一共进行5次,效果是判断链表值是否递减
15. 所以我们的目标是,通过输入值,使得排成的链表的值是递减的
我们并没有修改过链表的val域,所以它的值就是原始值
```
(gdb) x /12x 0x6032d0
0x6032d0 <node1>: 0x000000010000014c 0x00000000006032e0
0x6032e0 <node2>: 0x00000002000000a8 0x00000000006032f0
0x6032f0 <node3>: 0x000000030000039c 0x0000000000603300
0x603300 <node4>: 0x00000004000002b3 0x0000000000603310
0x603310 <node5>: 0x00000005000001dd 0x0000000000603320
0x603320 <node6>: 0x00000006000001bb 0x0000000000000000
```
按照值域大小对节点排序是:node3->node4->node5->node6->node1->node2
这里是一个反向的思维,我们希望最终排成的链表是这样的,而排成链表的形式是由我们输入的数据确定的,
由下面的图可知,我们排成的链表顺序,就是与输入数据的顺序是相同的,不过这里所说的输入数据,是指被7减过的数据

目标顺序是3 4 5 6 1 2,所以原始输入数据应当为4 3 2 1 6 5
 0
点赞
收藏
分享
CSAPP-Bomb Lab 思路记录
相关推荐










0 条评论
