

Q learning 算法:每次更新都用到了 Q 现实和 Q 估计。
参数含义:
-
 -greedy 是用在决策上的一种策略, 比如 = 0.9 时, 就说明有90% 的情况我会按照 Q 表的最优值选择行为, 10% 的时间使用随机选行为。
-greedy 是用在决策上的一种策略, 比如 = 0.9 时, 就说明有90% 的情况我会按照 Q 表的最优值选择行为, 10% 的时间使用随机选行为。 -
 是学习率, 来决定这次的误差有多少是要被学习的, 是一个小于1 的数。
是学习率, 来决定这次的误差有多少是要被学习的, 是一个小于1 的数。 -
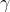 是对未来 reward 的衰减值:
是对未来 reward 的衰减值:

=1:未来没有任何衰变的奖励, 也就是机器人能清清楚楚地看到之后所有步的全部价值;
=(0~1):可以看出Q(s1) 是有关于之后所有的奖励, 但这些奖励正在衰减, 离 s1 越远的状态衰减越严重;
=0:只能摸到眼前的 reward, 同样也就只在乎最近的大奖励.










