Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。Yolov5s网络是Yolov5系列中深度最小,特征图的宽度最小的网络。后面的3种都是在此基础上不断加深,不断加宽。
网络结构:
1、模型参数配置:【YOLOV5-5.x 源码解读】yolov5s.yaml_满船清梦压星河HK的博客-CSDN博客_yolov5s
2、模块实现:
【YOLOV5-5.x 源码解读】common.py_满船清梦压星河HK的博客-CSDN博客
3、模型搭建:【YOLOV5-5.x 源码解读】yolo.py_满船清梦压星河HK的博客-CSDN博客_yolov5代码详解


(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone(主干网络,用来提取特征):Focus结构,BottleneckCSP结构、SPP结构
(3)Head:PANet+Detect
1、输入端
(1)Mosaic数据增强
【YOLOV5-5.x 源码解读】datasets.py_满船清梦压【YOLOV5-5.x 源码解读】datasets.py_满船清梦压
Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接 ,变相的等价于增大了mini-batch。
详见:[DeepLearning] Batch, Mini Batch, Batch Norm相关概念 - 知乎

这里首先要了解为什么要进行Mosaic数据增强呢?
在平时项目训练时,小目标的AP一般比中目标和大目标低很多(yolov5不适合检测小目标)。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。
如上表所示,Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。
但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。
针对这种状况,Yolov4的作者采用了Mosaic数据增强的方式。
主要有几个优点:
- 丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
- 减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
复试提问点:
1、你在比赛中用了哪些数据增强方式?
生成大小不同的图片、旋转、平移
2、yolov5用了哪些数据增强方式?
训练阶段: mosaic+ hsv色域增强(色调、饱和度、亮度) + 上下左右翻转
测试阶段: letterbox(自适应图片缩放)
(深度学习模型输入图片的尺寸为正方形,而数据集中的图片一般为长方形,粗暴的resize会使得图片失真,采用letterbox可以较好的解决这个问题。该方法可以保持图片的长宽比例,剩下的部分采用灰色填充。)
3、为什么不采用其他的数据增强方式?(适用情况)
尝试过一些其他方法,发现对mAP没有什么帮助,同时还延长了训练时间
4、除了这些,你还知道哪些数据增强方法 /你还尝试了哪些训练方法
cutout数据增强,给图片随机添加随机大小的方块噪声 ,目的是提高泛化能力和鲁棒性。
mixup数据增强:按比例融合两张图片
load 文件夹中的图片/视频 + 用到很少 load web网页中的数据。
5、为什么图像旋转、裁剪、放缩这些方法能有效增大样本量,它们不都是同一张图片吗
一个欠训练的神经网络会认为经过数据增强处理后的图片是不同、独特的图片
(2) 自适应锚框计算
【YOLOV5-5.x 源码解读】autoanchor.py_满船清梦压星河HK的博客-CSDN博客
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。
【论文理解】理解yolov3的anchor、置信度和类别概率_DLUT_yan的博客-CSDN博客_yolo置信度
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距(loss),再反向更新,迭代网络参数。
因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

yolov5初始化了9个anchors,在三个Detect层使用(3个feature map)中使用,每个feature map的每个grid_cell都有三个anchor进行预测。分配的规则是:尺度越大的feature map越靠前,相对原图的下采样率越小,感受野越小,所以相对可以预测一些尺度比较小的物体,所有分配到的anchors越小;尺度越小的feature map越靠后,相对原图的下采样率越大,感受野越大,所以相对可以预测一些尺度比较大的物体,所有分配到的anchors越大。即可以在小特征图(feature map)上检测大目标,也可以在大特征图上检测小目标。
yolov5根据工程经验得到了这么3组anchors,对于很多数据集而言确实挺合适的。但是也不能保证这3组anchors就适用于所有的数据集,所有yolov5还有一个anchor进化的策略:使用k-means和遗传进化算法,找到与当前数据集最吻合的anchors。
复试提问点:
1、为什么要有anchor,不能直接输出坐标吗?
anchor box其实就是从训练集的所有ground truth box中统计(使用k-means)出来的在训练集中最经常出现的几个box形状和尺寸。比如,在某个训练集中最常出现的box形状有扁长的、瘦高的和宽高比例差不多的正方形这三种形状。我们可以预先将这些统计上的先验(或来自人类的)经验加入到模型中,这样模型在学习的时候,瞎找的可能性就更小了些。
anchor box其实就是对预测的对象范围进行约束,有助于模型快速收敛
2、yolov5在3个detect层都输出了anchor,为什么要这样做?
可以小特征图(feature map)上检测大目标,也可以在大特征图上检测小目标,这样就能同时检测小目标和大目标。
3、为什么yolo要用k-means算法,它的距离度量是怎么做的?
通过k-means算法可以找到更合适的anchor,通过经验手工设定achor虽然能应用在大多数场景,但对于一些复杂特殊的场景可能不能很好应用,所以使用k-means和遗传进化算法算法来让achor自适应新的场景。yolov5论文中作者发现使用欧氏距离来计算效果不是很好,使用了1-IOU来表示距离,如果如果bbox与对应的簇中心(anchor)IOU越大,则距离越近(1-IOU)越小)
4、什么是遗传进化算法?
遗传算法是一种借鉴生物遗传进化机制开发的一种自适应算法,群体通过不断进行遗传和进化,按照优胜劣汰的规则将适应度较高的个体更多的遗传到下一代来获得优良个体。
在yolov5中使用遗传算法随机对anchors的wh进行变异,如果变异后效果变得更好(使用anchor_fitness方法计算得到的fitness(适应度)进行评估)就将变异后的结果赋值给anchors,如果变异后效果变差就跳过,默认变异1000次。
(3)自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
比如Yolo算法中常用416*416,608*608等尺寸,比如对下面800*600的图像进行缩放。

但Yolov5代码中对此进行了改进,也是Yolov5推理速度能够很快的一个不错的trick。
因此在Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。

图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。
第一步:计算缩放比例

原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。
第二步:计算缩放后的尺寸

原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。
第三步:计算黑边填充数值

将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到8个像素,再除以2,即得到图片高度两端需要填充的数值。
此外,需要注意的是:
a.这里填充的是黑色,即(0,0,0),而Yolov5中填充的是灰色,即(114,114,114),都是一样的效果。
b.训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
c.为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余。
复试提问点:
1、什么是自适应缩放?和普通的缩放有什么区别?如上
2、怎么做到添加最少的黑边?普通缩放是直接将缩放后短边剩余部分全部填充为黑边,而自适应缩放在填充黑边时只将短边填充到短边向上取整的32的倍数,从而让黑边最小化
2、 Backbone
【YOLOV5-5.x 源码解读】common.py_满船清梦压星河HK的博客-CSDN博客
 (1)Focus结构
(1)Focus结构


原理:Focus模块在v5中是图片进入backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图
作用:减少计算量(减少循环次数),增加速度。
yolov5中的Focus模块的理解_小菜的博客-CSDN博客_focus结构
(2)Conv结构
这个函数是整个网络中最基础的组件,由卷积层 + BN层 + 激活函数 组成,具体结构如下图:

Conv:提取特征。通过卷积核和图像做矩阵乘法,卷积核起到滤波器的作用,从而提取特征。
(1)原始图像通过与卷积核的数学运算,可以提取出图像的某些指定特征(features)。
(2)不同卷积核,提取的特征也是不一样的。
(3)提取的特征一样,不同的卷积核,效果也不一样。
bn:约束神经网络每一层输出的数据分布,从而加速模型收敛
SiLU:起到非线性的作用
(3)C3结构


C3结构将输入通过卷积划分为两部分,其中一部分经过Bottlenneck进一步提取特征,与另一部分经过拼接,由于只有一部分会参与Bottlenneck,因此在不影响特征提取能力的情况下降低了计算量、节约了内存成本。Bottlenneck提取特征的过程是先经过1*1卷积融合各通道信息,再通过3*3卷积进一步提取特征,同时进行残差连接。(残差连接:将特征映射与经过若干次卷积后的特征映射进行相加,解决网络退化问题(所谓网络退化就是随着层数增加,模型效果反而变差),这种恒等相加在反向传播时能有效解决梯度消失问题,因为恒等相加在反向传播中梯度值是1)
(4)SPP(空间金字塔池化 Spatial pyramid pooling layer)
这个模块的主要目的是为了将更多不同分辨率的特征进行融合,得到更多的信息。
SPP模块具体的结构如下所示:


如:在SPP模块中,使用k={1*1,5*5,9*9,13*13}的最大池化的方式,再将不同尺度的特征图进行Concat操作。
通过spp模块实现局部特征和全局特征(所以空间金字塔池化结构的最大的池化核要尽可能的接近等于需要池化的featherMap的大小)的featherMap级别的融合,丰富最终特征图的表达能力,从而提高MAP
复试提问点:
每个模块的作用、输入输出
3、head
YOLOv5 head = PANet+Detect

(1)PANet
Yolov5 的 Neck 部分采用了 PANet 结构,Neck 主要用于生成特征金字塔。特征金字塔会增强模型对于不同缩放尺度对象的检测,从而能够识别不同大小和尺度的同一个物体。
PANet 结构是在FPN的基础上引入了 Bottom-up path augmentation 结构。
特征图金字塔网络FPN(Feature Pyramid Networks)主要是通过融合高低层特征提升目标检测的效果,尤其可以提高小尺寸目标的检测效果。自上而下的过程是把更抽象、语义更强的高层特征图进行上采样(upsampling),而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。横向连接的两层特征在空间尺寸相同,这样做可以利用底层定位细节信息。(低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。)
Bottom-up path augmentation结构可以充分利用网络浅特征进行分割,网络浅层特征信息对于目标检测非常重要,因为目标检测是像素级别的分类浅层特征多是边缘形状等特征。PANet 在 FPN 的基础上加了一个自底向上方向的增强,使得顶层 feature map 也可以享受到底层带来的丰富的位置信息,从而提升了大物体的检测效果。如下图所示

FPN层自顶向下传达强语义特征,而Bottom-up path augmentation则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合。
(2)Detect
YOLOv5 采用了与 YOLOv3 相同的head网络,都是 1*1 的卷积结构,并有三组output,输出的特征图大小分辨为:
- bs * 255 * 80 * 80;
- bs * 255 * 40 * 40;
- bs * 255 * 20 * 20;
其中,bs是batch size,255 的计算方式为 [na * (nc + 1 + 4)] ,具体参数含义如下:
- na(number of anchor) 为每组 anchor 的尺度数量(YOLOv5中一共有 3 组anchor,每组有3个尺度);
- nc 为number of class (coco的class 为80);
- 1 为前景背景的置信度score;
- 4 为中心点坐标和宽高;
最后,输出的特征图上会应用锚定框,并生成带有类别概率、置信度得分和包围框的最终输出向量。
4、输出端
(1)目标框回归


(2)跨网格预测策略

yolov5采用了跨网格匹配规则,如下图所示,绿点表示该gt bbox中心,现在需要额外考虑其2个最近的邻域网格的anchor也作为该gt bbox的正样本,明显增加了正样本的数量。

代码实现逻辑:通过build_targets函数为每个feature map上的三个anchor筛选相应的正样本。筛选条件是比较GT和anchor的宽比和高比,大于一定的阈值就是负样本(背景),反之正样本(有物体)。筛选到的各个feature的各个anchor的正样本信息(image_index, anchor_index, gridy, gridx),传入__call__函数,通过这个信息去筛选pred每个grid预测得到的信息,保留对应grid_cell上的正样本。通过build_targets筛选的GT中的正样本和pred筛选出的对应位置的预测样本进行计算损失。
(3)NMS非极大值抑制
【YOLO v4】常见的非极大值抑制方法:(Hard) NMS、Soft NMS、DIoU NMS_满船清梦压星河HK的博客-CSDN博客
NMS原理及代码实现_Roger-Liu的博客-CSDN博客_nms代码
注意:有读者会有疑问,为什么不用CIOU_nms,而用DIOU_nms?
答:因为CIOU_loss,是在DIOU_loss的基础上,添加的影响因子,包含groundtruth标注框的信息,在训练时用于回归。
但在测试过程中,并没有groundtruth的信息,不用考虑影响因子,因此直接用DIOU_nms即可。
损失函数
【YOLOV5-5.x 源码解读】loss.py_满船清梦压星河HK的博客-CSDN博客
YOLOv5损失函数包含:
- localization loss,定位损失(预测框与GT框之间的误差)
- classification loss,分类损失
- confidence loss,置信度损失(框的目标性;objectness of the box)
总的损失函数:localization loss+classification loss+confidence loss
YOLOv5使用使用CIOU Loss作为定位损失,二元交叉熵损失函数计算分类损失和置信度损失
定位损失常用计算指标是IOU:
- IOU_Loss:主要考虑检测框和目标框重叠面积。
- GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
- DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
- CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息
目标检测回归损失函数简介:SmoothL1/IoU/GIoU/DIoU/CIoU Loss - 知乎

完整的损失函数由边界框回归损失(第一项)、置信度预测损失(第二三项)和类别预测损失(第四项)三部分构成。

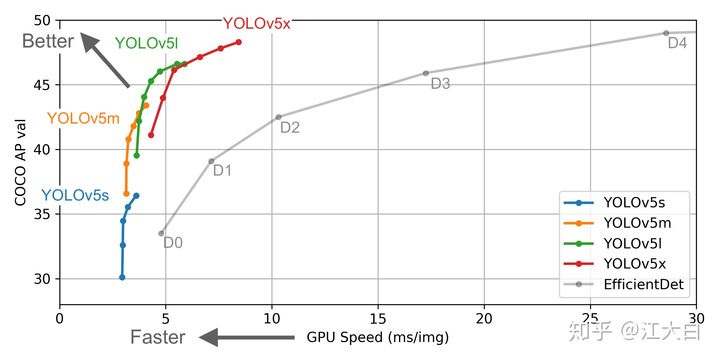
算法性能:
Yolov5作者也是在COCO数据集上进行的测试,大白在之前的文章讲过,COCO数据集的小目标占比,因此最终的四种网络结构,性能上来说各有千秋。
Yolov5s网络最小,速度最少,AP精度也最低。但如果检测的以大目标为主,追求速度,倒也是个不错的选择。
其他的三种网络,在此基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。