(1)涉及到的算法
1.监督学习:线性回归,逻辑回归,神经网络,SVM。
线性回归(下面第三行x0(i)其实是1,可以去掉)
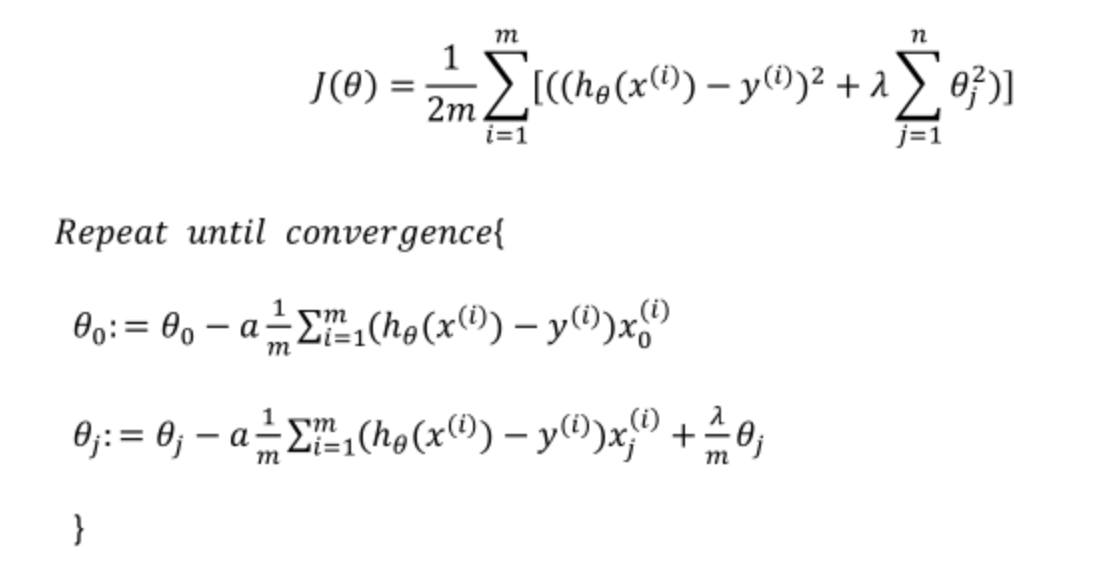
逻辑回归
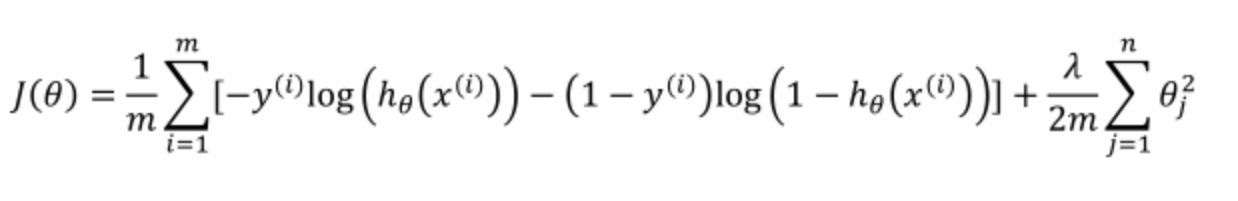
神经网络(写出前向传播即可,反向框架会自动计算)

SVM

2.非监督学习:聚类算法(K-mean),降维(PCA)
K-mean

PCA

3.异常检测

4.推荐系统

(2)策略
1.偏差与方差,正则化
训练误差减去人类最高水平为偏差(欠拟合),交叉验证集误差减训练误差为方差(过拟合);
正则化解决方差问题,不对θ0正则化;
2.学习曲线
全过程观测偏差与方差,所以更全面。
3.误差分析
找到哪种原因造成误差最大,最该花时间的地方。
4.评价方法
尽量使用单一指标评价,准确率不适合类偏斜,用精确度和召回率判定
精确度是预测的视角(预测为正样本中有多少是正样本),召回率是样本视角(正样本有多少被预测到了)
F1=2(PR)/(P+R)
5.数据集的拆分
训练集用于训练模型,,交叉验证集用于筛选模型/调参,测试集用来做最终评价。
6.上限分析
每一步假设输出完全正确时,能提高多少的正确率,提高最高的地方就是最该马上花时间解决的地方。
(3)应用
1.OCR
检测,分割,识别,现在常常不分割了,直接序列化识别。
2.大规模的机器学习
小批量的训练方法以及使用并行计算。
作者:你的雷哥
本文版权归作者所有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利。
