大家好,欢迎来到专栏《AutoML》,在这个专栏中我们会讲述AutoML技术在深度学习中的应用,这一期讲述可微分架构用于模型搜索的基本概念和流程。
作者&编辑 | 言有三
前面两期我们给大家介绍了基于强化学习和进化算法的模型结构搜索,它们的共同特点就是搜索空间是连续的,并且计算量很大,本期我们介绍可微分架构的网络搜索,其搜索空间是连续的,并且相比强化学习和进化算法具有计算优势。
1 简介
所谓的可微分,指的就是候选的网络结构单元,或者说搜索空间不是离散的,而是连续的,这样带来的好处就是可以通过梯度下降算法直接进行优化。
这样的搜索空间,优化的不只是有限的滤波核的尺寸或者卷积连接的模式,而是可以发现复杂的拓扑结构,并且卷积和循环网络可以同时实现。
这样一来,强化学习中用于产生结构单元的RNN Controller不需要了,一些框架中的代理模型也不需要了,整个流程更加简单。
2 基于可微分架构的网络搜索
下面我们以一个经典的算法来对使用可微分架构进行网络搜索的基本流程进行介绍,方法为DARTS(Differentiable Architecture Search),它通过搜索最优的cell,然后将cell组合成大网络。
2.1 基本思想
由于网络的空间是巨大的,首先要进行一些约束,主要是针对cell的约束。
(1) 一个cell必须由输入节点,中间节点,输出节点和边构成,并且DARTS规定了输入节点有两个,输出节点有一个。之所以考虑到两个,是为了兼容CNN和RNN。对于CNN来说,就是前面两层输出,对于RNN,就是输入和隐藏层状态。
(2) 输出节点是所有中间节点的通道拼接结果。
结构示意图如下:
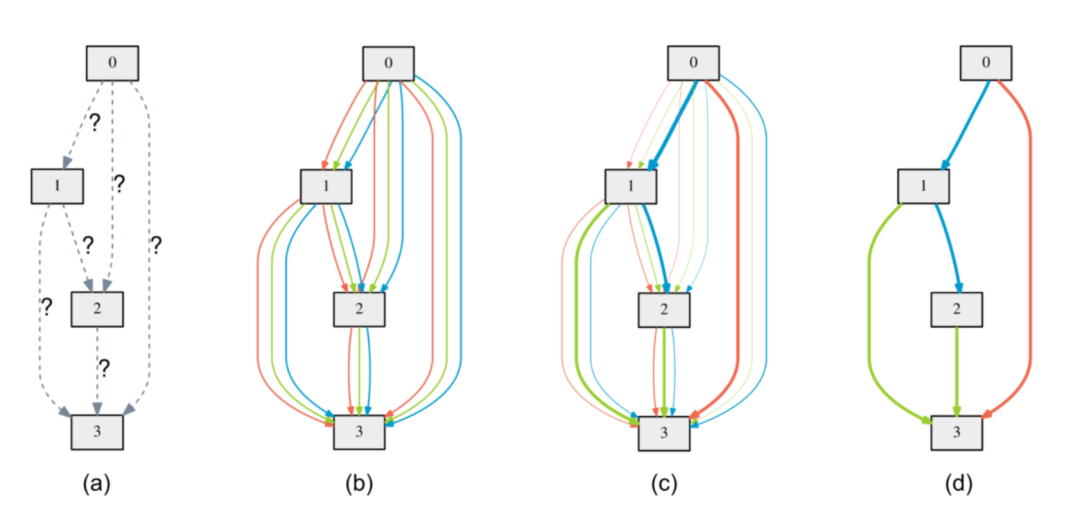
图(a)就是一个未经初始化的结构,其中没有展示两个输入节点,它们会一起输入到0,1和2都是中间节点,3是输出节点。图(b)中两个节点之间不同的颜色表示不同的转换操作,它们一起用加权的方式从输入到输出产生结果,如下式。

其中o表示不同操作,i表示当前节点,j表示序号小于i的所有节点。每一个操作被选中的概率用不同操作的softmax概率加权表示,如下:

如此一来,选择不同操作及其概率就是一个连续的过程,α就是要优化的参数,它和连接权重矩阵一样都可以用梯度下降算法进行优化。
2.2 优化过程
上面已经构建好了cell的结构以及需要搜索的连续参数空间,接下来就是进行优化,包括参数α和卷连接权重,这是一个双层优化问题,具体来说分两个步骤进行:

(1) 训练时,固定α参数矩阵,只优化连接权重W。
(2) 验证时,固定W参数矩阵,只优化α参数矩阵。
如此循环迭代,直到满足终止条件,下面是伪代码表示。

值得注意的是,在学习过程中,训练集和验证集比例大小为1:1,这与大部分任务设置不同。
在学习完α参数矩阵后,只保留其中概率值最大的操作,就得到了最终的结构单元,如上图中(c)到(d)的过程。
下图展示了在CIFAR10上学习到的一些单元:

其中normal cell就是不改变特征图大小,reduction就是改变特征图大小。










