一、基于业务角度建模
Elasticsearch 适用范围非常广,包括电商、快递、日志等各行各业。涉及索引层面的设计,和业务贴合紧密。
其一:业务一定要细分。
分成哪几类数据,每类数据归结为一个索引还是多个索引,这是产品经理、架构师、项目经理要讨论敲定的问题。比如大数据类的数据,可以按照业务数据分为微博索引、微信索引、Twiiter 索引、Facebook 索引等。
其二:多个业务类型需不需要跨索引检索?
跨索引检索的痛点是字段不统一、不一致,需要写非常复杂的 bool 组合查询语句来实现。为了避免这种情况,最好的方式就是提前建模。每一类业务数据的相同或者相似字段,采取统一建模的方式。
下面我们举一个实际的例子加以分析。微博、微信、Twitter、Facebook 都有的字段,可以设计如下:
| 字段名称 | 字段中文含义 | 字段类型 |
|---|---|---|
| publish_time | 发布时间 | date |
| author | 作者 | keyword |
| cont | 正文内容 | text |
这样设计的好处是:字段统一,写查询 DSL 无需特殊处理,非常快捷方便。所以,在设计阶段,多个业务索引数据要尽可能地“求同存异”。具体来说:
-
求同指的是相同或者相近含义字段,一定要统一字段名、统一字段类型;
-
存异指的则是特定业务数据特有字段类型,可以独立设计字段名称和类型。
比如微博信息来源字段有手机 App 或者网页等,别的业务索引如果没有,独立建模就可以。
类似这些建模信息可以统一 Excel 存储,统一 git 多人协作管理。
多索引管理一般优先推荐使用模板(template)和 别名(alias)结合的方式。
-
模板的特点:相同前缀名称的索引可以归结为一大类,一次创建,N 多索引共享,非常方便。
-
别名的特点:多个索引可以映射到一个别名,方便多索引以相同的名称统一对外提供服务。

二、基于数据量角度建模
对于时序性数据(日志数据、大数据类数据)等,强烈建议基于时间切分索引,具体如下图所示。

当然,其他可用的方案非常多,这里我列举如下,供你选型参考。
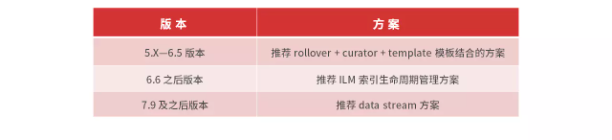
由此可见,时序管理数据的优点非常明显。
-
其一是灵活。基于时间切分索引非常方便,删除数据属于物理删除。
-
其二则是快速。特定业务数据配合冷热集群架构,确保高配机器对应热数据,提升检索效率和用户体验。
三、基于 Setting 层面建模
Setting 层面又分为静态 Setting 和动态 Setting 两种。
- 静态 Settings:一旦设置后,后续不可修改。如
number_of_shards - 动态 Setting:索引创建后,后面随时可以更新,如
number_of_replicas,max_result_window,refresh_interval
仅就建模阶段最核心的问题,拆解如下。
-
问题一:索引设置多少个分片?多少个副本?
这里有个认知前提,就是主分片数一旦设置后就不可以修改,副本分片数可以灵活动态调整。
主分片设计一般会考量总体数据量、集群节点规模,这点在集群规划层面会着重强调。一般主分片数要考虑集群未来动态扩展,通常设置为数据节点的 1 倍或者 1~3 倍之间的值。
副本分片是保证集群的高可用性,普通业务场景建议至少设置一个副本。
-
问题二:refresh_interval 一般设置多大?
默认值 1s,这意味着在写入阶段,每秒都会生成一个分段。
refresh_interval 的目的是:数据由 index buffer 的堆内存缓存区刷新到堆外内存区域,形成 segment,以使得搜索可见。
在实际业务场景里,如果写入的数据不需要近实时搜索可见,可以适当地在模板、索引层面调大这个值,当然也可以动态调整,比如调整为 30s 或者 60s。
-
问题三:max_result_window 要不要修改默认值?
这里同样有个认知前提,就是对于深度翻页的 from + size 实现,越往后翻页越慢。其实你对比看主流搜索引擎,比如 Google、百度、360、Bing 均不支持一下跳转到最后一页,这就是最大翻页上限限制。
其实在基本业务层面也很好理解,按照相关度返回结果,前面几页是最相关的,越往后相关度越低。比如默认值 10000,也就是说如果每页显示 10 条数据,可以翻 1000 页。基本业务场景已经足够了。因此不建议调大该值。
如果需要向后翻页查询,推荐 search_after 查询方式。如果需要全量遍历或者全量导出数据,推荐 scroll 查询方式。
-
问题四:管道预处理怎么用?
管道预处理的好处很多,虽然 5.X 版本就有了这个功能,但实战环境用起来还不多。
管道 ingest pipeline 就相当于大数据的 ETL 抽取、转换、加载的环节,或者类似 logstash filter 处理环节。一些数据打标签、字段类型切分、加默认字段、加默认值等的预处理操作都可以借助 ingest pipelie 实现。
这里给出索引层面 Setting 设置的简单模板,供你进一步学习参考,如下定义了 indexed_at 缺省的管道,同时在索引 my_index_0001 指定了该缺省管道,这样做的好处,是每个新增的数据都会加了插入时刻的时间戳:indexed_at 字段,无需我们在业务层面手动处理,非常灵活和方便。
更多设置,推荐阅读官方文档,地址如下:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules.html#index-modules-settings
PUT _ingest/pipeline/indexed_at
{
"description": "Adds indexed_at timestamp to documents",
"processors": [
{
"set": {
"field": "_source.indexed_at",
"value": "{{_ingest.timestamp}}"
}
}
]
}
PUT my_index_0001
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3,
"refresh_interval": "30s",
"index": {
"default_pipeline": "indexed_at"
}
},
"mappings": {
"properties": {
"cont": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}四、基于 Mapping 层面建模
Mapping 层面核心是字段名称、字段类型、分词器选型、多字段 multi_fields 选型,以及字段细节(是否索引、是否存储等)的敲定。
4.1 字段命名要规范
索引名称不允许用大写,字段名称官方没有限制,但是可以参考 Java 编码规范。我还真见过学员用中文或者拼音命名的,非常不专业,大家一定要避免。
4.2 字段类型要合理
要结合业务类型选择合适的字段类型。比如 integer 能搞定的,就不要用 long、float 或 double。
注意,字符串类型在 5.X 版本之后分为两种类型:
-
一种是 keyword,适合精准匹配、排序和聚合操作;
-
另一种是 text,适合全文检索。默认值 text & keyword 组合不见得是最优的,选型时候要结合业务选择。比如优先选择 keyword 类型,keyword 走倒排索引更快。
再举个例子,实战中情感值介于 0~100 之间,50 代表中性,0~50 代表负面,50~100 代表正面。如果使用 integer 查询的时候要 range query,而实际存储可以增加字段:0~50 设置为 -1,50 设置为 0,50~100 设置为 1,三种都是 keyword 类型,检索时直接走 term 检索会非常快。
4.3 分词器要灵活
实战中中文分词器用得比较多,中文分词又分为 ansj,结巴,IK 等。以 IK 举例,可以细分为 ik_smart 粗粒度分词、ik_max_word 细粒度分词。
在工作中,要结合业务选择合适的分词器,分词器一旦设定是不可以修改的,除非 reindex。
分词器选型后,都会有动态词典的更新问题。更新的前提是不要仅使用开源插件原生词典,而是要在平时业务中自己多积累特定业务数据词典、词库。
如果要动态更新:一般推荐第三方更新插件借助数据库更新实现。如果普通分词都不能满足业务需要,可以考虑 ngram 自定义分词方式实现更细粒度分词。
4.4 multi_fields 适机使用
同一个字段根据需要可以设置多种类型。实战业务中,对用特定中文词明明存在,却无法召回的情况,采用字词混合索引的方式得以满足。
所谓字词混合,实际就是 standard 分词器实现单字拆解,以及 ik_max_word 实现中文切词结合的方式。检索的时候 bool 对两种分词器结合,就可以实现相对精准的召回效果。
PUT mix_index
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"standard": {
"type": "text",
"analyzer": "standard"
},
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
POST mix_index/_search
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"content": "佟大"
}
},
{
"match_phrase": {
"content.standard": "佟大"
}
}
]
}
}
}为了方便你记忆和使用,这里我把字段细节总结在如下这张表格中:
| 核心参数 | 默认值 | 释义 |
| enabled | true | 仅适用于 Mapping 顶层以及 Object 对象,设置为 false 后该字段将不再被解析。 |
| index | true | 控制是否对字段值进行索引,设置为 false 的字段不能被查询。 |
| doc_values | true | 正排索引,除了 text 类型外的其他类型默认开启,用于聚合和排序分析。 |
| fielddata | false | 是否为 text 类型启动 fielddata,实现 text 字段排序和聚合分析。 |
| store | false | 是否存储该字段值。 |
| coerce | true | 是否开启自动数据类型转换功能,比如 字符串转数字、浮点转整型。true 代表可以转换,false 代表不可以转换。 |
| fields | 根据业务需要而定 | 灵活使用多字段解决多样的业务需求。 |
| dynamic | true | 控制 mapping 的动态自动更新。 |
| date_detection | true | 是否自动识别类型。 |
再来分析一下数据建模的流程,如下图所示。:

首先,根据业务选择合适的数据类型。
注意字符串类型分为两种 text 和 keyword类型;尽量选择贴近实际大小的数据类型;nested 和 join 复杂类型需根据业务特点选型,具体会在下一部分详细阐述。
其次,判定是否需要检索,如果不需要,index 设置为 false 即可。
然后,判定是否需要排序和聚合操作,如果不需要可以设置 doc_values 为 false。
最后,考虑一下是否需要另行存储,会结合使用 store 和 _source 字段。
Mapping 层面要强调的是:尽量不要使用默认的 dynamic 动态字段类型,强烈建议 strict 严格控制字段,避免字段“暴涨”导致不可预知的风险,比如字段数超过默认 1000 个的上限、磁盘大于预期的激增等。
五、基于复杂索引关联建模
5.1 宽表方案
这是空间换时间的方案,就是允许部分字段冗余存储的存储方式。实战举例如下。
用户索引:user。
博客索引:blogpost。
一个用户可以发表多篇博客。按照传统的 MySQL 建表思想:两个表建立个用户外键,即可搞定一切。而对于 Elasticsearch,我们更愿意在每篇博文后面都加上用户信息(这就是宽表存储的方案),看似存储量大了,但是一次检索就能搞定搜索结果。
PUT user/_doc/1
{
"name": "John Smith",
"email": "john@smith.com",
"dob": "1970/10/24"
}
PUT blogpost/_doc/2
{
"title": "Relationships",
"body": "It's complicated...",
"user": {
"id": 1,
"name": "John Smith"
}
}
GET /blogpost/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "relationships"
}
},
{
"match": {
"user.name": "John"
}
}
]
}
}
}5.2 nested 方案
适用场景:1 对少量,子文档偶尔更新、查询频繁的场景。
如果需要索引对象数组并保持数组中每个对象的独立性,则应使用嵌套 Nested 数据类型而不是对象 Oject 数据类型。
nested 文档的优点是可以将父子关系的两部分数据(如博客+评论)关联起来,我们可以基于nested 类型做任何的查询。但缺点是查询速度相对较慢,更新子文档需要更新整篇文档。
5.3 join父子文档方案
适用场景:子文档数据量要明显多于父文档的数据量,存在 1 对多量的关系;子文档更新频繁的场景。
比如 1 个产品和供应商之间就是 1 对 N 的关联关系。当使用父子文档时,使用 has_child 或者 has_parent 做父子关联查询。优点是父子文档可独立更新,但维护 Join 关系需要占据部分内存,查询较 Nested 更耗资源。
注意:5.X 之前版本叫父子文档(多 type 实现),6.X 之后高版本是 join 类型(单 type 类型)。
5.4 业务层面实现关联
需通过多次检索获取所需的关键字段,业务层面自己写代码实现。
5.5 小结
以上四种方式便是 Elasticsearch 能实现的全量多表关联方案。实战建模阶段,一定要结合自己的业务场景,尽量往上靠,先通过 kibana dev tool 模拟实现,找到契合自己业务的多表关联方案。
此外还要强调的是:多表关联都会有性能问题,数据量极大且检索性能要求高的场景需要慎用。这里我摘取了官方文档对应的描述如下,供你参考。
尤其应该避免多表关联。Nested 嵌套可以使查询慢几倍,而 Join 父子关系可以使查询慢数百倍。
六、总结
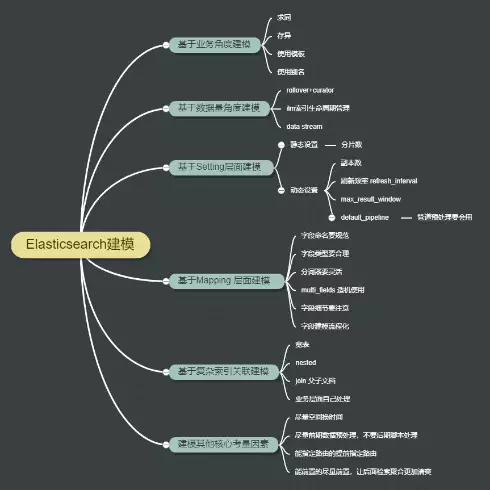
-
尽量空间换时间:能多个字段解决的不要用脚本实现。
-
尽量前期数据预处理,不要后期脚本。优先选择 ingest process 数据预处理实现,尽量不要留到后面 script 脚本实现。
-
能指定路由的提前指定路由。写入的时候指定路由,检索的时候也同样适用路由。
-
能前置的尽量前置,让后面检索聚合更加清爽。比如 index sorting 前置索引字段排序是非常好的方式。
数据建模是 Elasticsearch 开发实战中非常重要的一环,也是项目管理角度中的设计环节的重中之重,你一定要重视!千万不要着急写业务代码,以“代码之前,设计先行”作为行动准绳。
参考资料:
1.微信公众号(铭毅天下Elasticsearch )-《干货 | Elasticsearch 数据建模指南》










