算法简介:
在支持离线查询的与子树有关的题目中可以 离线处理每个点的信息然后
离线处理每个点的信息然后 查询。
查询。
常见的题目有查询某子树颜色数量即相关信息。
算法思想:
考虑最简单的处理方法:对每个点都遍历一次子树所有节点求相关信息,复杂度为 ,明显没有实际应用意义。
,明显没有实际应用意义。
仔细思考过程,我们可以发现每个点的信息求出来了之后,只对当前子树和父节点有作用,对其同深度的子树没有任何意义,反而我们还需要求一遍之后清除记录之后才能求其他点的信息,不然会冲突。
此时算法的瓶颈出现了:遍历的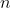 不可避免,能不能把每个点的求解降复杂度呢?
不可避免,能不能把每个点的求解降复杂度呢?
想想求解的过程,其实遍历时的信息相加和判断是很优秀的,重点在于有些点的信息我们要留给父节点,有的信息要删除避免影响其他子树的答案。删除信息过程耗了太多时间。
那能不能不删呢?
对每一棵树,最先遍历的子树肯定要删,不然会影响其他子树。那么最后一个子树我们就不用删了。为了最大化优化复杂度,我们把重子树放在最后无疑是最佳的。那么递归这个过程,由于定义,总复杂度不会超过,得到可行解。
板子:
/*keep on going and never give up*/
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl '\n'
#define inf 1e18
#define fast std::ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
const int maxn=2e5+20;
vector<int>e[maxn];
int siz[maxn],mson[maxn],col[maxn];
void dfs1(int x,int fa){//重子节点
siz[x]=1;
for(auto y:e[x]){
if(y==fa)continue;
dfs1(y,x);
if(siz[y]>siz[mson[x]])mson[x]=y;
siz[x]+=siz[y];
}
}
int cnt[maxn],ans[maxn],now_ans=0;
void change(int x,int fa,int type){//更新cnt
cnt[col[x]]+=type;
if(type==1&&cnt[col[x]]==1)now_ans++;
if(type==-1&&cnt[col[x]]==0)now_ans--;
for(auto y:e[x])
if(y!=fa) change(y,x,type);
}
void dfs2(int x,int fa,bool f){
for(auto y:e[x])
if(y!=fa&&y!=mson[x])
dfs2(y,x,1);//先轻再重
if(mson[x]!=0)
dfs2(mson[x],x,0);
cnt[col[x]]++;
if(cnt[col[x]]==1)now_ans++;
for(auto y:e[x])
if(y!=fa&&y!=mson[x]) change(y,x,1);//删轻
ans[x]=now_ans;
if(f)change(x,fa,-1);
}
signed main(){
fast
int n;cin>>n;
for(int i=1,x,y;i<n;i++){
cin>>x>>y;e[x].push_back(y),e[y].push_back(x);
}
for(int i=1;i<=n;i++) cin>>col[i];
dfs1(1,0);
dfs2(1,0,0);
int m;cin>>m;
for(int i=1,x;i<=m;i++)
cin>>x,cout<<ans[x]<<endl;
}










