pivot_table函数
pivot_table(
data= 表格,
index= 行,
columns= 列,
values= 值,
aggfunc= 计数函数,
margins= True # 汇总统计
)aggfunc调用函数, 不带括号
不带括号时, 调用的是这个函数本身, 是一个函数对象
带括号时, 调用的是函数的执行结果
透视表中的行,列, 不能同时成为透视表的值
如果某列既是透视表的 行或列, 又是透视表中分类计数的值, 需要在透视前复制该列为新的独立列
否则会报错, Grouper for ... not 1-dimensional
margins 汇总统计中, 将各组内所有元素降维汇总到一起, 再统计
np.count_nonzero()是用于, 统计矩阵中非零元素 的个数
df.fillna(0) 只会填充np.nan 和None 而不会填充空字符串等其他非数值元素
计数函数
- 'count'
- len
- np.count_nonzero
实验 区分这三种计数函数对缺失值的处理
'''表格准备'''
import pandas as pd
import numpy as np
行 = ['A', 'B', 'C', 'D', 'E']
值 = [1, np.nan, '', ' ', '1']
df_jishu = pd.DataFrame([行, 值], index= ['行', '值']).T
df_jishu.insert(
loc= 1,
column= '列',
value= ['数值', 'np.nan', '空字符串', '空格字符串', '其他非空字符串']
)
df_jishu_1 = pd.concat([df_jishu, df_jishu]).reset_index(drop= True)
df_jishu_1
'''
实验1
区分三种计数函数对缺失值的处理
'''
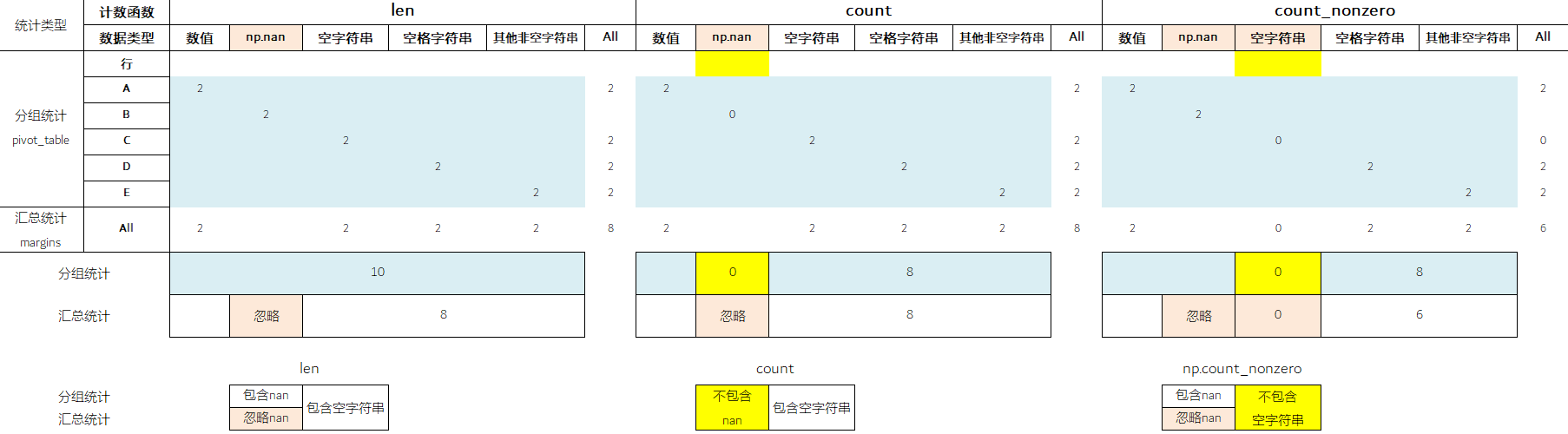
df_jishu_2 = df_jishu_1.pivot_table(
index= '行',
columns= '列',
values= '值',
aggfunc= [len, 'count', np.count_nonzero],
margins= True
)
df_jishu_2.columns.names = ['计数函数', '数据类型']
df_jishu_2
'''
笔记1
计数函数 不同于 计算函数
比如 len 不同于 加减乘除或sum
笔记1.1
在计算函数中 含有非数值类型 会报错
笔记1.2
在计算函数中 含有np.nan 会导致结果为np.nan
笔记2
margins 汇总统计中, 将各组内所有元素降维汇总到一起, 再统计
笔记3
三种计数函数的区别 见下表
'''
参考文献
透视表的计数方法
函数带括号与不带
聚合统计的各种方法
np.count_nonzero
https://blog.csdn.net/bin083/article/details/98122531
https://blog.csdn.net/ITLearnHall/article/details/80894365
https://www.51cto.com/article/665805.html
https://blog.csdn.net/zfhsfdhdfajhsr/article/details/109813613









